|
||
|
基于深度学习识别RiPPs前体肽及裂解位点
合成生物学
2022, 3 (6):
1262-1276.
DOI:10.12211/2096-8280.2022-016
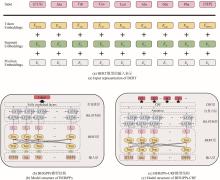
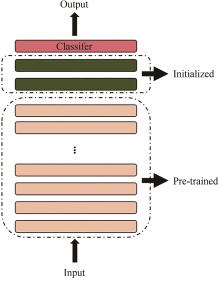
得益于基因测序技术的快速发展,基因组测序数据呈现爆炸式增长,核糖体合成和翻译后修饰肽(RiPPs)是近十年逐渐进入人们视野的一大类肽类天然产物。这类化合物在自然界中分布极其广泛,具有丰富的结构多样性和生物活性多样性,是天然药物的重要来源。RiPPs的发现主要依赖低通量生物实验,传统方法精确但成本高昂,随着新型计算机技术的更新迭代,包括antiSMASH、RiPP-PRISM等在内的生物信息学工具能够极大加速RiPPs挖掘进程,但依然无法突破基于同源性方法(例如搜索保守的生物合成酶)的限制——无法有效识别具有不同生物合成机制的新型RiPPs。在这里,本文首次基于自然语言处理预训练模型BERT,提出四种可以完全依赖序列数据识别RiPPs而非基于同源性及基因组上下文信息的深度学习模型,通过对各模型进行验证分析和对比,最终确定在RiPPs识别赛道上表现卓越的最佳模型BERiPPs(bidirectional language model for enhancing the performance of identification of RiPPs precursor peptides)。BERiPPs能够在不考虑基因组背景的情况下以无偏见的方式识别RiPPs前体肽,并可通过条件随机场生成对前导肽裂解位点的预测,为高通量挖掘全新RiPPs提供了思路,并在一定程度下揭示了前体肽和修饰酶间的生物学底层关系。  View image in article
图8
BERiPPs与RiPPMiner及antiSMASH对比
正文中引用本图/表的段落
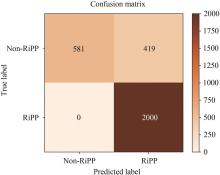
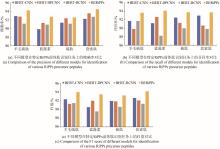
BERiPPs-CRF模型通过对氨基酸序列的标注进行识别,从而间接生成对RiPPs前体肽裂解位点的预测。从实体识别的角度来说,BERiPPs-CRF依然表现了较高的水平,精确率、召回率和F1值分别为90.45%、91.33%和90.88%。但从对RiPPs前体肽裂解位点预测的角度来看,其重点在于能否准确判断标签B(即核心肽起始氨基酸)所在的位置。同样受限于数据集中各类RiPPs样本的数量以及不同RiPPs家族所展现的前体切割规则的差异,在对RiPPs前体肽裂解位点的预测上准确率出现了明显的两极差异。例如对套索肽裂解位点的准确率达到了70%以上,Ⅰ、Ⅱ型羊毛硫肽裂解位点的预测准确率也超过了60%,而小型的RiPPs家族的预测结果则不太理想。如果把与真实裂解位点相差±5个氨基酸的预测也纳入考虑范围之内,那么整体预测的准确率为80.67%。本文将基于机器学习的RiPPMiner用同样的测试数据集进行预测,与BERiPPs-CRF模型对比结果如图8(a)所示。对于没有准确识别真实裂解位点的样本而言,模型预测的位点与实际位点相隔越近,则越有RiPPs研究的借鉴意义,如果模型能够做到把预测与真实位点之间的间隔控制在±5甚至±3、±1个氨基酸以内,其模型的价值也将按倍数增加。因此,为了更直观地展现预测位点与实际位点的偏差程度,本文根据统计学规则引入一个新的评估指标偏位度
为了进一步验证基于预训练模型的深度学习方法在天然产物挖掘领域的可行性以及评估BERiPPs在处理未知RiPPs前体肽上的能力,本研究于美国国家生物技术信息中心检索了1000个原核生物基因组,通过ORF分析工具找到ORF所在区域并翻译为相应的蛋白序列,将所有长度短于200个氨基酸的ORF作为BERiPPs的输入,共识别得到6319个RiPPs前体肽。同时,将上述1000个原核生物基因组通过antiSMASH进行全基因组分析,基于基因同源性找到了4386个RiPPs,其中3905个RiPPs所在区域与BERiPPs预测结果重合[图8(b)]。通过对比可以发现BERiPPs不仅识别到了89.03%的由antiSMASH进行全基因组分析得到的RiPPs,还将可能的未知RiPPs范围进一步扩大了60%左右,展现了在不考虑基因组背景的情况下仅基于候选前体肽序列挖掘全新RiPPs的潜力,并从一定程度上揭示了未知的新型RiPPs家族可能不完全适用于现有天然产物生物合成途径的规则。本文基于上述6319个由BERiPPs检测到的未经标注的RiPPs前体肽尝试对在通用域语料上预训练的BERT模型进行深入预训练,仅采用MLM任务且只对MLM计算损失,通过预测随机遮掩的氨基酸单元来进一步增加BERT在特定领域下抽取特征的能力,但这一点并没有在下游任务中得以体现。不难推测,实质性的提升依然需要大量的未标注样本。
本文的其它图/表
|




{kind=link}