|
||
|
DeepSeek模型分析及其在AI辅助蛋白质工程中的应用
合成生物学
2025, 6 (3):
636-650.
DOI:10.12211/2096-8280.2025-041
2025年年初,杭州深度求索人工智能基础技术研究有限公司发布并开源了其自主研发的DeepSeek-R1对话大模型。该模型具备极低的推理成本和出色的思维链推理能力,在多种任务上能够媲美甚至超越闭源的GPT-4o和o1模型,引发了国际社会的高度关注。此外,DeepSeek模型在中文对话上的优异表现以及免费商用的策略,在国内引发了部署和使用的热潮,推动了人工智能技术的普惠与发展。本文围绕DeepSeek模型的架构设计、训练方法与推理机制进行系统性分析,探讨其核心技术在AI蛋白质研究中的迁移潜力与应用前景。DeepSeek模型融合了多项自主创新的前沿技术,包括多头潜在注意力机制、混合专家网络及其负载均衡、低精度训练等,显著降低了Transformer模型的训练和推理成本。尽管DeepSeek模型原生设计用于人类语言的理解与生成,但其优化技术对同样基于Transformer模型的蛋白质预训练语言模型具有重要的参考价值。借助DeepSeek所采用的关键技术,蛋白质语言模型在训练成本、推理成本等方面有望得到显著降低。 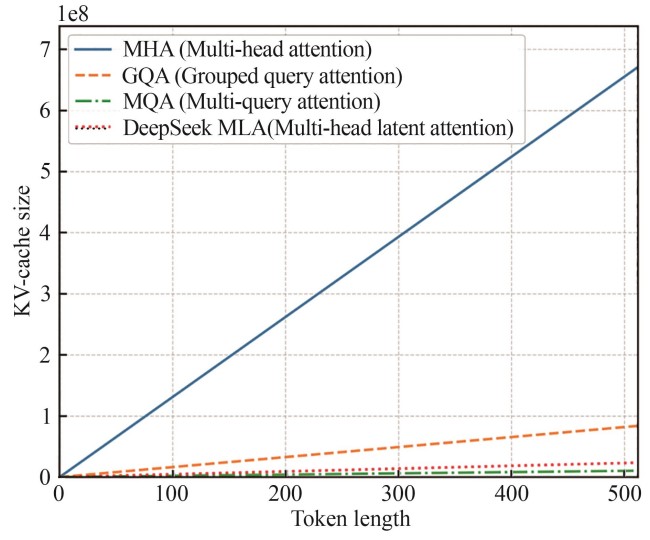 View image in article
图3
不同注意力机制的KV-Cache内存占用与输出长度的关系示意图
正文中引用本图/表的段落
针对上述挑战,DeepSeek团队提出了一种新的注意力机制——多头潜在注意力机制(MLA)。该机制通过将键值向量压缩至一个固定维度的隐空间中,并在注意力计算前将其还原至原始表示空间,从而有效降低了KV-Cache的显存占用。实验表明,MLA能够在保持高质量生成的同时,显著减少模型推理时的显存消耗。尽管该方法在训练阶段引入了额外的压缩编码成本,但在推理过程中,得益于矩阵乘法的结合律特性,可以将压缩与注意力计算融合为一次高效的矩阵操作,从而不会增加额外的计算负担。图3以注意力头数64,模型隐层大小8192,层数80的Transformer模型为例展示了不同注意力机制(MQA、GQA与MLA)的KV-Cache显存占用随输出长度变化的趋势,其中GQA的分组数为8,计算公式为DeepSeek-V2中给出的注意力复杂度计算公式[12]。可以看出,随着序列长度的增加,MLA所需的缓存空间明显低于MHA及GQA,略高于MQA。然而,MLA在生成质量方面优于MQA。
本文的其它图/表
|


{kind=link}