Use of the UGA terminator as a tryptophan codon in yeast mitochondria
1
1979
... 遗传密码(决定DNA中三个核苷酸为一组的密码子转译为蛋白质中氨基酸序列的规则)曾被认为是不可改变的,且可被基因编码的氨基酸种类局限于20种.随后的研究打破了这一结论,表明生物的遗传密码在不同物种间也存在一定的差异性.例如,在酿酒酵母的线粒体中,终止密码子UGA也能编码色氨酸[1].在包括人类在内的许多物种中,UGA亦可被用于编码常规氨基酸之外的第21种氨基酸,即硒代半胱氨酸[2].这些发现均暗示着遗传密码在生物体内具有可拓展和被重编的潜力. ...
Selenocysteine, a highly specific component of certain enzymes, is incorporated by a UGA-directed co-translational mechanism
1
1988
... 遗传密码(决定DNA中三个核苷酸为一组的密码子转译为蛋白质中氨基酸序列的规则)曾被认为是不可改变的,且可被基因编码的氨基酸种类局限于20种.随后的研究打破了这一结论,表明生物的遗传密码在不同物种间也存在一定的差异性.例如,在酿酒酵母的线粒体中,终止密码子UGA也能编码色氨酸[1].在包括人类在内的许多物种中,UGA亦可被用于编码常规氨基酸之外的第21种氨基酸,即硒代半胱氨酸[2].这些发现均暗示着遗传密码在生物体内具有可拓展和被重编的潜力. ...
A general method for site-specific incorporation of unnatural amino acids into proteins
1
1989
... 自然界生物按照其对应的密码子表来基因编码蛋白质合成所需的20种天然氨基酸(不包括硒代半胱氨酸和吡咯赖氨酸).在生物体内,如磷酸化、乙酰化、泛素化等翻译后修饰是丰富天然氨基酸结构进而拓展蛋白质功能的主要途径,在许多生命过程的调控中发挥着关键的作用.蛋白质氨基酸种类的拓展亦可以通过向目标蛋白中引入非天然氨基酸的方式来实现.技术手段包括往细胞中注射化学合成的氨酰化tRNA[3],或改造营养缺陷型菌株使其可利用氨基酸类似物[4].此外,以Peter G. Schultz等为代表的研究人员开发了一种基因密码子拓展方法,通过往细胞内引入改造后的翻译工具来实现基因编码非天然氨基酸,为拓展蛋白质的结构和功能开辟了新的路径[5].密码子拓展技术的核心是需要引入一套正交的外源翻译工具,即能特异性识别非天然氨基酸的氨酰-tRNA合成酶以及能识别空白密码子的配对tRNA[图1(a)].同时,该工具配对不能与宿主细胞中的内源性氨酰-tRNA合成酶或tRNA发生交叉反应[图1(b)].此外,通过对其他核心翻译元件(如延伸因子和核糖体)进行设计和改造,可进一步实现对密码子拓展系统的优化,从而提高非天然氨基酸被特异性地引入到目标蛋白中的效率[6,7,8].本节将重点围绕以氨酰-tRNA合成酶/tRNA配对为代表的翻译元件正交性以及多种其他翻译元件的改造方法进行介绍讨论. ...
Toward the experimental codon reassignment in vivo: protein building with an expanded amino acid repertoire
1
1999
... 自然界生物按照其对应的密码子表来基因编码蛋白质合成所需的20种天然氨基酸(不包括硒代半胱氨酸和吡咯赖氨酸).在生物体内,如磷酸化、乙酰化、泛素化等翻译后修饰是丰富天然氨基酸结构进而拓展蛋白质功能的主要途径,在许多生命过程的调控中发挥着关键的作用.蛋白质氨基酸种类的拓展亦可以通过向目标蛋白中引入非天然氨基酸的方式来实现.技术手段包括往细胞中注射化学合成的氨酰化tRNA[3],或改造营养缺陷型菌株使其可利用氨基酸类似物[4].此外,以Peter G. Schultz等为代表的研究人员开发了一种基因密码子拓展方法,通过往细胞内引入改造后的翻译工具来实现基因编码非天然氨基酸,为拓展蛋白质的结构和功能开辟了新的路径[5].密码子拓展技术的核心是需要引入一套正交的外源翻译工具,即能特异性识别非天然氨基酸的氨酰-tRNA合成酶以及能识别空白密码子的配对tRNA[图1(a)].同时,该工具配对不能与宿主细胞中的内源性氨酰-tRNA合成酶或tRNA发生交叉反应[图1(b)].此外,通过对其他核心翻译元件(如延伸因子和核糖体)进行设计和改造,可进一步实现对密码子拓展系统的优化,从而提高非天然氨基酸被特异性地引入到目标蛋白中的效率[6,7,8].本节将重点围绕以氨酰-tRNA合成酶/tRNA配对为代表的翻译元件正交性以及多种其他翻译元件的改造方法进行介绍讨论. ...
Probing protein structure and function with an expanded genetic code
1
1995
... 自然界生物按照其对应的密码子表来基因编码蛋白质合成所需的20种天然氨基酸(不包括硒代半胱氨酸和吡咯赖氨酸).在生物体内,如磷酸化、乙酰化、泛素化等翻译后修饰是丰富天然氨基酸结构进而拓展蛋白质功能的主要途径,在许多生命过程的调控中发挥着关键的作用.蛋白质氨基酸种类的拓展亦可以通过向目标蛋白中引入非天然氨基酸的方式来实现.技术手段包括往细胞中注射化学合成的氨酰化tRNA[3],或改造营养缺陷型菌株使其可利用氨基酸类似物[4].此外,以Peter G. Schultz等为代表的研究人员开发了一种基因密码子拓展方法,通过往细胞内引入改造后的翻译工具来实现基因编码非天然氨基酸,为拓展蛋白质的结构和功能开辟了新的路径[5].密码子拓展技术的核心是需要引入一套正交的外源翻译工具,即能特异性识别非天然氨基酸的氨酰-tRNA合成酶以及能识别空白密码子的配对tRNA[图1(a)].同时,该工具配对不能与宿主细胞中的内源性氨酰-tRNA合成酶或tRNA发生交叉反应[图1(b)].此外,通过对其他核心翻译元件(如延伸因子和核糖体)进行设计和改造,可进一步实现对密码子拓展系统的优化,从而提高非天然氨基酸被特异性地引入到目标蛋白中的效率[6,7,8].本节将重点围绕以氨酰-tRNA合成酶/tRNA配对为代表的翻译元件正交性以及多种其他翻译元件的改造方法进行介绍讨论. ...
Expanding and reprogramming the genetic code of cells and animals
2
2014
... 自然界生物按照其对应的密码子表来基因编码蛋白质合成所需的20种天然氨基酸(不包括硒代半胱氨酸和吡咯赖氨酸).在生物体内,如磷酸化、乙酰化、泛素化等翻译后修饰是丰富天然氨基酸结构进而拓展蛋白质功能的主要途径,在许多生命过程的调控中发挥着关键的作用.蛋白质氨基酸种类的拓展亦可以通过向目标蛋白中引入非天然氨基酸的方式来实现.技术手段包括往细胞中注射化学合成的氨酰化tRNA[3],或改造营养缺陷型菌株使其可利用氨基酸类似物[4].此外,以Peter G. Schultz等为代表的研究人员开发了一种基因密码子拓展方法,通过往细胞内引入改造后的翻译工具来实现基因编码非天然氨基酸,为拓展蛋白质的结构和功能开辟了新的路径[5].密码子拓展技术的核心是需要引入一套正交的外源翻译工具,即能特异性识别非天然氨基酸的氨酰-tRNA合成酶以及能识别空白密码子的配对tRNA[图1(a)].同时,该工具配对不能与宿主细胞中的内源性氨酰-tRNA合成酶或tRNA发生交叉反应[图1(b)].此外,通过对其他核心翻译元件(如延伸因子和核糖体)进行设计和改造,可进一步实现对密码子拓展系统的优化,从而提高非天然氨基酸被特异性地引入到目标蛋白中的效率[6,7,8].本节将重点围绕以氨酰-tRNA合成酶/tRNA配对为代表的翻译元件正交性以及多种其他翻译元件的改造方法进行介绍讨论. ...
... 氨酰-tRNA合成酶/tRNA配对是翻译过程中的核心工具,保证其正交性是进行技术开发和相应下游应用挖掘的关键.氨酰-tRNA合成酶/tRNA配对的正交性包含两个层面:第一,tRNA的正交性,即外源引入的工具tRNA(用于匹配空白密码子的tRNA)只能被对应的工具酶特异性地识别,而不能与内源的其他氨酰-tRNA合成酶发生交叉反应;第二,氨酰-tRNA合成酶的正交性,即外源的氨酰-tRNA合成酶工具能特异性地识别外源添加的非天然氨基酸[图1(b)][6,7,8]. ...
Expanding and reprogramming the genetic code
3
2017
... 自然界生物按照其对应的密码子表来基因编码蛋白质合成所需的20种天然氨基酸(不包括硒代半胱氨酸和吡咯赖氨酸).在生物体内,如磷酸化、乙酰化、泛素化等翻译后修饰是丰富天然氨基酸结构进而拓展蛋白质功能的主要途径,在许多生命过程的调控中发挥着关键的作用.蛋白质氨基酸种类的拓展亦可以通过向目标蛋白中引入非天然氨基酸的方式来实现.技术手段包括往细胞中注射化学合成的氨酰化tRNA[3],或改造营养缺陷型菌株使其可利用氨基酸类似物[4].此外,以Peter G. Schultz等为代表的研究人员开发了一种基因密码子拓展方法,通过往细胞内引入改造后的翻译工具来实现基因编码非天然氨基酸,为拓展蛋白质的结构和功能开辟了新的路径[5].密码子拓展技术的核心是需要引入一套正交的外源翻译工具,即能特异性识别非天然氨基酸的氨酰-tRNA合成酶以及能识别空白密码子的配对tRNA[图1(a)].同时,该工具配对不能与宿主细胞中的内源性氨酰-tRNA合成酶或tRNA发生交叉反应[图1(b)].此外,通过对其他核心翻译元件(如延伸因子和核糖体)进行设计和改造,可进一步实现对密码子拓展系统的优化,从而提高非天然氨基酸被特异性地引入到目标蛋白中的效率[6,7,8].本节将重点围绕以氨酰-tRNA合成酶/tRNA配对为代表的翻译元件正交性以及多种其他翻译元件的改造方法进行介绍讨论. ...
... 氨酰-tRNA合成酶/tRNA配对是翻译过程中的核心工具,保证其正交性是进行技术开发和相应下游应用挖掘的关键.氨酰-tRNA合成酶/tRNA配对的正交性包含两个层面:第一,tRNA的正交性,即外源引入的工具tRNA(用于匹配空白密码子的tRNA)只能被对应的工具酶特异性地识别,而不能与内源的其他氨酰-tRNA合成酶发生交叉反应;第二,氨酰-tRNA合成酶的正交性,即外源的氨酰-tRNA合成酶工具能特异性地识别外源添加的非天然氨基酸[图1(b)][6,7,8]. ...
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
The role of orthogonality in genetic code expansion
3
2019
... 自然界生物按照其对应的密码子表来基因编码蛋白质合成所需的20种天然氨基酸(不包括硒代半胱氨酸和吡咯赖氨酸).在生物体内,如磷酸化、乙酰化、泛素化等翻译后修饰是丰富天然氨基酸结构进而拓展蛋白质功能的主要途径,在许多生命过程的调控中发挥着关键的作用.蛋白质氨基酸种类的拓展亦可以通过向目标蛋白中引入非天然氨基酸的方式来实现.技术手段包括往细胞中注射化学合成的氨酰化tRNA[3],或改造营养缺陷型菌株使其可利用氨基酸类似物[4].此外,以Peter G. Schultz等为代表的研究人员开发了一种基因密码子拓展方法,通过往细胞内引入改造后的翻译工具来实现基因编码非天然氨基酸,为拓展蛋白质的结构和功能开辟了新的路径[5].密码子拓展技术的核心是需要引入一套正交的外源翻译工具,即能特异性识别非天然氨基酸的氨酰-tRNA合成酶以及能识别空白密码子的配对tRNA[图1(a)].同时,该工具配对不能与宿主细胞中的内源性氨酰-tRNA合成酶或tRNA发生交叉反应[图1(b)].此外,通过对其他核心翻译元件(如延伸因子和核糖体)进行设计和改造,可进一步实现对密码子拓展系统的优化,从而提高非天然氨基酸被特异性地引入到目标蛋白中的效率[6,7,8].本节将重点围绕以氨酰-tRNA合成酶/tRNA配对为代表的翻译元件正交性以及多种其他翻译元件的改造方法进行介绍讨论. ...
... 氨酰-tRNA合成酶/tRNA配对是翻译过程中的核心工具,保证其正交性是进行技术开发和相应下游应用挖掘的关键.氨酰-tRNA合成酶/tRNA配对的正交性包含两个层面:第一,tRNA的正交性,即外源引入的工具tRNA(用于匹配空白密码子的tRNA)只能被对应的工具酶特异性地识别,而不能与内源的其他氨酰-tRNA合成酶发生交叉反应;第二,氨酰-tRNA合成酶的正交性,即外源的氨酰-tRNA合成酶工具能特异性地识别外源添加的非天然氨基酸[图1(b)][6,7,8]. ...
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
Universal rules and idiosyncratic features in tRNA identity
1
1998
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Engineering a tRNA and aminoacyl-tRNA synthetase for the site-specific incorporation of unnatural amino acids into proteins in vivo
1
1997
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Expanding the genetic code of Escherichia coli
1
2001
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Major anticodon-binding region missing from an archaebacterial tRNA synthetase
1
1999
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Editing of errors in selection of amino acids for protein synthesis
1
1992
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
An expanding genetic code
1
2005
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
An expanded eukaryotic genetic code
1
2003
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Progress toward an expanded eukaryotic genetic code
1
2003
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Site‐specific incorporation of an unnatural amino acid into proteins in mammalian cells
1
2002
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
Genetic incorporation of unnatural amino acids into proteins in mammalian cells
1
2007
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
A genetically encoded photocaged amino acid
2
2004
... tRNA是翻译过程中氨基酸的运输工具,每种tRNA上带有的被对应氨酰-tRNA合成酶所识别的特征元素决定了tRNA水平的正交性[9].理想的正交氨酰-tRNA合成酶/tRNA配对不会与宿主细胞中的天然氨基酸、内源性氨酰-tRNA合成酶或tRNA发生交叉反应.早期研究通过对内源的氨酰-tRNA合成酶和配对tRNA进行设计改造,成功开发出在tRNA水平正交的氨酰-tRNA合成酶/tRNA配对,使其能独立于内源的工具配对行使特定的功能[10].另一种思路则是从进化关系较远的生物体中选择氨酰-tRNA合成酶/tRNA配对进行改造,以降低交叉反应的发生概率.例如,古菌Methanococcus janaschii的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(MjTyrRS/tRNATyr)于2001年被引入到大肠杆菌中,用于编码合成含有O-甲基-L-酪氨酸的蛋白质[11].在大肠杆菌中选择上述工具配对的原因包括:①MjtRNATyr的氨基酸接纳茎上第一个碱基对为C-G(大肠杆菌是G-C),可有效地防止被内源TyrRS酶识别[12];②TyrRS不具有对于底物氨基酸的编辑校对机制[13],有益于非天然氨基酸的引入.这些特征极大地降低了正交工具改造的难度,且改造后的MjTyrRS/tRNACUA配对因在大肠杆菌中具有良好的正交性和较高的活性,得到了广泛的应用[14].然而,该工具配对在酵母和哺乳细胞等真核系统中不正交,该配对在真核系统中的应用则受到了限制.基于相似原理,可用于真核系统的多个氨酰-tRNA合成酶/tRNA配对被相继开发出来.例如,源自大肠杆菌的酪氨酰-tRNA合成酶/酪氨酸tRNA配对(EcTyrRS/tRNACUA)和亮氨酰-tRNA合成酶/亮氨酸tRNA配对(EcLeuRS/tRNACUA)被改造为真核生物中的密码子拓展工具[15,16,17,18,19],但由于这些配对工具在大肠杆菌中和一些其他细菌中不正交,故又不适用于原核系统. ...
... 作为细胞中最古老的酶之一,氨酰-tRNA合成酶是保证翻译过程严格按照遗传密码子表执行的核心元件.通过长期的进化,氨酰-tRNA合成酶中氨基酸结合口袋这一特定结构能特异性地识别对应的氨基酸,从而保证氨酰-tRNA合成酶对底物的正交性.因此,开发能特异性识别非天然氨基酸的工具酶需要对氨酰-tRNA合成酶中氨基酸结合口袋及其他关键结合区域进行设计改造和定向进化.基于上述思路和策略,不同类型的氨酰-tRNA合成酶被用于改造,多种用于基因密码子拓展的工具酶被成功地开发出来,实现了把超过200种的非天然氨基酸特异性地引入到生物体蛋白中[28,29].例如,包含β-芳香族侧链或γ-芳香族侧链的非天然氨基酸可通过改造MjTyrRS酶引入[30];特异性改造EcLeuRS酶可实现O-甲基-L-酪氨酸、α-氨基辛酸以及光敏感的邻硝基苄基半胱氨酸等的引入[19]. ...
Pyrrolysine is not hardwired for cotranslational insertion at UAG codons
2
2007
... 吡咯赖氨酰-tRNA合成酶/吡咯赖氨酸tRNA配对(PylRS/tRNAPyl)存在于一些产甲烷的古菌和细菌中,是编码吡咯赖氨酸(第22种氨基酸)的工具.因其在多种生物系统中(包括细菌和真核生物)都具有高正交性,适合作为在原核系统和真核系统中的通用性密码子拓展工具进行改造.针对tRNAPyl的正交性维持机制已积累了较为全面的研究基础:通过体内活性和氨酰动力学测试,tRNAPyl的氨基酸接纳茎中G73位点和第一个碱基对以及T环碱基对G51:C63是重要的识别特征元素[20].PylRS酶氮末端结构域紧密地贴合在由tRNAPyl 的T环和极小可变环组成的凹面上,这一结构特征使得PylRS/tRNAPyl配对自身能够特异性结合,且能避免其他内源tRNA中较长可变环与PylRS酶的非特异性结合[21].此外, PylRS酶具有氨基酸底物识别可塑性高和不识别tRNA反密码子环等优良特性,进一步促使PylRS/tRNACUA配对成为目前应用范围最广泛的编码工具[20]. ...
... [20]. ...
Crystal structures reveal an elusive functional domain of pyrrolysyl-tRNA synthetase
1
2017
... 吡咯赖氨酰-tRNA合成酶/吡咯赖氨酸tRNA配对(PylRS/tRNAPyl)存在于一些产甲烷的古菌和细菌中,是编码吡咯赖氨酸(第22种氨基酸)的工具.因其在多种生物系统中(包括细菌和真核生物)都具有高正交性,适合作为在原核系统和真核系统中的通用性密码子拓展工具进行改造.针对tRNAPyl的正交性维持机制已积累了较为全面的研究基础:通过体内活性和氨酰动力学测试,tRNAPyl的氨基酸接纳茎中G73位点和第一个碱基对以及T环碱基对G51:C63是重要的识别特征元素[20].PylRS酶氮末端结构域紧密地贴合在由tRNAPyl 的T环和极小可变环组成的凹面上,这一结构特征使得PylRS/tRNAPyl配对自身能够特异性结合,且能避免其他内源tRNA中较长可变环与PylRS酶的非特异性结合[21].此外, PylRS酶具有氨基酸底物识别可塑性高和不识别tRNA反密码子环等优良特性,进一步促使PylRS/tRNACUA配对成为目前应用范围最广泛的编码工具[20]. ...
Mutually orthogonal nonsense-suppression systems and conjugation chemistries for precise protein labeling at up to three distinct sites
2
2019
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
... [22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
Genetically encoding N ε -acetyllysine in recombinant proteins
1
2008
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
A facile system for genetic incorporation of two different noncanonical amino acids into one protein in Escherichia coli
1
2010
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
Evolution of multiple, mutually orthogonal prolyl-tRNA synthetase/tRNA pairs for unnatural amino acid mutagenesis in Escherichia coli
1
2012
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
Mutually orthogonal pyrrolysyl-tRNA synthetase/tRNA pairs
1
2018
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
Methanomethylophilus alvus Mx1201 provides basis for mutual orthogonal pyrrolysyl tRNA/aminoacyl-tRNA synthetase pairs in mammalian cells
1
2018
... 开发在tRNA水平相互正交的编码工具是同时基因编码多种非标准氨基酸的关键性环节,也是该领域备受关注的研究方向.早期研究的关注点在于将一种非天然氨基酸引入到蛋白质合成中,随着近年来新型工具配对的开发和的优化方法的改进,在目标蛋白质中同时基因编码2~3种非天然氨基酸已成为可能[22,23].在细胞中编码多种非天然氨基酸合成的蛋白质,需要借助相互正交的氨酰-tRNA合成酶/tRNA配对实现.即在不与内源的翻译系统发生交叉反应的前提下,引入的多对外源氨酰-tRNA合成酶/tRNA配对之间亦不能发生相互作用[图 1(b)][8].一些已开发的用于编码非天然氨基酸的氨酰-tRNA合成酶/tRNA工具配对自身已经具备相互正交性.例如,古菌来源的MjTyrRS/tRNACUA和PylRS/tRNAPyl配对(tRNAPyl被改造用于抑制终止密码子UAA)可分别将2种非天然氨基酸同时引入大肠杆菌氯霉素乙酰转移酶中[24].进一步配合大肠杆菌衍生工具配对EcTrpRS/tRNA,则可实现同时基因编码3种不同的非天然氨基酸[22].近年来,海量的基因组与宏基因组数据成为开发新型氨酰-tRNA合成酶/tRNA的重要资源,通过生物信息学的深度分析挖掘,一些新型的PylRS/tRNAPyl配对被挖掘和发现,可用于开发同类型相互正交的非天然氨基酸编码工具[25,26,27]. ...
Upgrading aminoacyl-tRNA synthetases for genetic code expansion
2
2018
... 作为细胞中最古老的酶之一,氨酰-tRNA合成酶是保证翻译过程严格按照遗传密码子表执行的核心元件.通过长期的进化,氨酰-tRNA合成酶中氨基酸结合口袋这一特定结构能特异性地识别对应的氨基酸,从而保证氨酰-tRNA合成酶对底物的正交性.因此,开发能特异性识别非天然氨基酸的工具酶需要对氨酰-tRNA合成酶中氨基酸结合口袋及其他关键结合区域进行设计改造和定向进化.基于上述思路和策略,不同类型的氨酰-tRNA合成酶被用于改造,多种用于基因密码子拓展的工具酶被成功地开发出来,实现了把超过200种的非天然氨基酸特异性地引入到生物体蛋白中[28,29].例如,包含β-芳香族侧链或γ-芳香族侧链的非天然氨基酸可通过改造MjTyrRS酶引入[30];特异性改造EcLeuRS酶可实现O-甲基-L-酪氨酸、α-氨基辛酸以及光敏感的邻硝基苄基半胱氨酸等的引入[19]. ...
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Polyspecific pyrrolysyl-tRNA synthetases from directed evolution
2
2014
... 作为细胞中最古老的酶之一,氨酰-tRNA合成酶是保证翻译过程严格按照遗传密码子表执行的核心元件.通过长期的进化,氨酰-tRNA合成酶中氨基酸结合口袋这一特定结构能特异性地识别对应的氨基酸,从而保证氨酰-tRNA合成酶对底物的正交性.因此,开发能特异性识别非天然氨基酸的工具酶需要对氨酰-tRNA合成酶中氨基酸结合口袋及其他关键结合区域进行设计改造和定向进化.基于上述思路和策略,不同类型的氨酰-tRNA合成酶被用于改造,多种用于基因密码子拓展的工具酶被成功地开发出来,实现了把超过200种的非天然氨基酸特异性地引入到生物体蛋白中[28,29].例如,包含β-芳香族侧链或γ-芳香族侧链的非天然氨基酸可通过改造MjTyrRS酶引入[30];特异性改造EcLeuRS酶可实现O-甲基-L-酪氨酸、α-氨基辛酸以及光敏感的邻硝基苄基半胱氨酸等的引入[19]. ...
... 当讨论氨酰-tRNA合成酶工具用于密码子拓展的有效性和可行性时,其底物水平的正交性是相对而非绝对的.即相比上文提到的“一对一”识别特异性的案例,还存在“一对多”识别的情况.一些氨酰-tRNA合成酶存在底物多特异性(polyspecific),能够同时识别多种天然或者非天然氨基酸[31].例如,野生型的PylRS可识别超过20种赖氨酸衍生物[32],改造后可实现特异性地识别N-乙酰化赖氨酸及其衍生物或者带有脂肪族侧链的非天然氨基酸[29,31].多特异性现象的存在可能是氨酰-tRNA合成酶在进化过程中缺乏同类型氨基酸底物的竞争所致,该现象的发现对应用某些廉价氨基酸衍生底物进行酶活性测试和定向进化相关研究有着重要的意义. ...
Expanding the genetic code
1
2005
... 作为细胞中最古老的酶之一,氨酰-tRNA合成酶是保证翻译过程严格按照遗传密码子表执行的核心元件.通过长期的进化,氨酰-tRNA合成酶中氨基酸结合口袋这一特定结构能特异性地识别对应的氨基酸,从而保证氨酰-tRNA合成酶对底物的正交性.因此,开发能特异性识别非天然氨基酸的工具酶需要对氨酰-tRNA合成酶中氨基酸结合口袋及其他关键结合区域进行设计改造和定向进化.基于上述思路和策略,不同类型的氨酰-tRNA合成酶被用于改造,多种用于基因密码子拓展的工具酶被成功地开发出来,实现了把超过200种的非天然氨基酸特异性地引入到生物体蛋白中[28,29].例如,包含β-芳香族侧链或γ-芳香族侧链的非天然氨基酸可通过改造MjTyrRS酶引入[30];特异性改造EcLeuRS酶可实现O-甲基-L-酪氨酸、α-氨基辛酸以及光敏感的邻硝基苄基半胱氨酸等的引入[19]. ...
Pyrrolysyl-tRNA synthetase: an ordinary enzyme but an outstanding genetic code expansion tool
2
2014
... 当讨论氨酰-tRNA合成酶工具用于密码子拓展的有效性和可行性时,其底物水平的正交性是相对而非绝对的.即相比上文提到的“一对一”识别特异性的案例,还存在“一对多”识别的情况.一些氨酰-tRNA合成酶存在底物多特异性(polyspecific),能够同时识别多种天然或者非天然氨基酸[31].例如,野生型的PylRS可识别超过20种赖氨酸衍生物[32],改造后可实现特异性地识别N-乙酰化赖氨酸及其衍生物或者带有脂肪族侧链的非天然氨基酸[29,31].多特异性现象的存在可能是氨酰-tRNA合成酶在进化过程中缺乏同类型氨基酸底物的竞争所致,该现象的发现对应用某些廉价氨基酸衍生底物进行酶活性测试和定向进化相关研究有着重要的意义. ...
... ,31].多特异性现象的存在可能是氨酰-tRNA合成酶在进化过程中缺乏同类型氨基酸底物的竞争所致,该现象的发现对应用某些廉价氨基酸衍生底物进行酶活性测试和定向进化相关研究有着重要的意义. ...
Designing logical codon reassignment-expanding the chemistry in biology
1
2015
... 当讨论氨酰-tRNA合成酶工具用于密码子拓展的有效性和可行性时,其底物水平的正交性是相对而非绝对的.即相比上文提到的“一对一”识别特异性的案例,还存在“一对多”识别的情况.一些氨酰-tRNA合成酶存在底物多特异性(polyspecific),能够同时识别多种天然或者非天然氨基酸[31].例如,野生型的PylRS可识别超过20种赖氨酸衍生物[32],改造后可实现特异性地识别N-乙酰化赖氨酸及其衍生物或者带有脂肪族侧链的非天然氨基酸[29,31].多特异性现象的存在可能是氨酰-tRNA合成酶在进化过程中缺乏同类型氨基酸底物的竞争所致,该现象的发现对应用某些廉价氨基酸衍生底物进行酶活性测试和定向进化相关研究有着重要的意义. ...
Adding new chemistries to the genetic code
1
2010
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Kinetic origin of substrate specificity in post-transfer editing by leucyl-tRNA synthetase
1
2018
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Upgrading protein synthesis for synthetic biology
1
2013
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Evolution of translation machinery in recoded bacteria enables multi-site incorporation of nonstandard amino acids
1
2015
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Continuous directed evolution of aminoacyl-tRNA synthetases
1
2017
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Methods for the directed evolution of proteins
1
2015
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Development of potent in vivo mutagenesis plasmids with broad mutational spectra
1
2015
... 在获得了tRNA水平正交的氨酰-tRNA合成酶/tRNA配对基础之上,针对氨酰-tRNA合成酶的后续改造主要集中在氨基酸底物识别口袋或编辑结构域的活性位点.传统的定向进化方法通常利用连续正反向迭代筛选原理,在建立氨基酸识别口袋突变体文库之后,通过连续正选择(抗生素抗性)和反选择(毒性蛋白产生)来分离可特异性引入非天然氨基酸的氨酰-tRNA合成酶变体[33].氨酰-tRNA合成酶的编辑活性位点决定自身的矫正活性,用于水解错配的氨基酸,对其进行改造亦可有效提高非天然氨基酸的引入效率.例如,对EcLeuRS酶编辑活性位点的失活突变可降低其识别天然底物亮氨酸的能力,从而提高翻译过程中非天然氨基酸的引入效率[34].除了传统方法,新一代蛋白质定向进化方法加速了氨酰-tRNA合成酶的开发.建立包含更多活性位点的突变体文库或者通过易错PCR 获得随机突变等方法,为获得更优质的正交配对提供了可能性[35].此外,多元自动化基因组工程(multiplex automated genome engineering, MAGE)和噬菌体辅助持续进化(phage-assisted continuous evolution, PACE)技术也在密码子扩展工具开发过程中起到了重要作用[36,37].MAGE技术可在细胞群内创建组合遗传多样性的大型突变体文库[38]. PACE技术的优势则在于不依赖已知的蛋白质结构,通过体内随机诱变,实施工具效率和细胞生长相耦联的筛选方法,不仅可以在短时间内获得目标突变体,还有助于揭示工具酶关键残基的未知功能[28,39]. ...
Rewiring translation for elongation factor Tu‐dependent selenocysteine incorporation
1
2013
... 理性设计和定向进化策略亦可有效地用于tRNA的改造和优化.例如,tRNA的受体茎是被延伸因子(elongation factor, EF-Tu)识别的特征元素,将大肠杆菌tRNASec的受体茎移植到tRNASer上,建立杂交tRNAUTu成功解决了EF-Tu无法识别tRNASec的问题[40].通过后续的定点诱变,获得了比野生型活性更高的突变体tRNAUTuX,从而推动了硒蛋白的高效合成[41].此外,通过对构建MjtRNATyr的突变体库和正反向筛选,获得了更容易被延伸因子EF-Tu 识别的突变体tRNA,有助于提高目标蛋白的产量[42].基于PylRS酶不识别tRNAPyl的反义密码子环特性,tRNAPyl反义密码子环可被任意改造,用于读取不同的密码子[43].通过对tRNAPyl反义密码茎的定向进化,可进一步筛选出翻译效率更高的tRNAPyl突变体(tRNAPly-Opt)[44].未来,随着生化原理解析的深入和相关技术的快速发展,tRNA这一核心翻译元件的开发优化有望进一步突破,实现从源头上推动密码子拓展技术的升级和应用. ...
A synthetic tRNA for EF‐Tu mediated selenocysteine incorporation in vivo and in vitro
1
2015
... 理性设计和定向进化策略亦可有效地用于tRNA的改造和优化.例如,tRNA的受体茎是被延伸因子(elongation factor, EF-Tu)识别的特征元素,将大肠杆菌tRNASec的受体茎移植到tRNASer上,建立杂交tRNAUTu成功解决了EF-Tu无法识别tRNASec的问题[40].通过后续的定点诱变,获得了比野生型活性更高的突变体tRNAUTuX,从而推动了硒蛋白的高效合成[41].此外,通过对构建MjtRNATyr的突变体库和正反向筛选,获得了更容易被延伸因子EF-Tu 识别的突变体tRNA,有助于提高目标蛋白的产量[42].基于PylRS酶不识别tRNAPyl的反义密码子环特性,tRNAPyl反义密码子环可被任意改造,用于读取不同的密码子[43].通过对tRNAPyl反义密码茎的定向进化,可进一步筛选出翻译效率更高的tRNAPyl突变体(tRNAPly-Opt)[44].未来,随着生化原理解析的深入和相关技术的快速发展,tRNA这一核心翻译元件的开发优化有望进一步突破,实现从源头上推动密码子拓展技术的升级和应用. ...
Evolution of amber suppressor tRNAs for efficient bacterial production of proteins containing nonnatural amino acids
1
2009
... 理性设计和定向进化策略亦可有效地用于tRNA的改造和优化.例如,tRNA的受体茎是被延伸因子(elongation factor, EF-Tu)识别的特征元素,将大肠杆菌tRNASec的受体茎移植到tRNASer上,建立杂交tRNAUTu成功解决了EF-Tu无法识别tRNASec的问题[40].通过后续的定点诱变,获得了比野生型活性更高的突变体tRNAUTuX,从而推动了硒蛋白的高效合成[41].此外,通过对构建MjtRNATyr的突变体库和正反向筛选,获得了更容易被延伸因子EF-Tu 识别的突变体tRNA,有助于提高目标蛋白的产量[42].基于PylRS酶不识别tRNAPyl的反义密码子环特性,tRNAPyl反义密码子环可被任意改造,用于读取不同的密码子[43].通过对tRNAPyl反义密码茎的定向进化,可进一步筛选出翻译效率更高的tRNAPyl突变体(tRNAPly-Opt)[44].未来,随着生化原理解析的深入和相关技术的快速发展,tRNA这一核心翻译元件的开发优化有望进一步突破,实现从源头上推动密码子拓展技术的升级和应用. ...
tRNAPyl: structure, function, and applications
1
2018
... 理性设计和定向进化策略亦可有效地用于tRNA的改造和优化.例如,tRNA的受体茎是被延伸因子(elongation factor, EF-Tu)识别的特征元素,将大肠杆菌tRNASec的受体茎移植到tRNASer上,建立杂交tRNAUTu成功解决了EF-Tu无法识别tRNASec的问题[40].通过后续的定点诱变,获得了比野生型活性更高的突变体tRNAUTuX,从而推动了硒蛋白的高效合成[41].此外,通过对构建MjtRNATyr的突变体库和正反向筛选,获得了更容易被延伸因子EF-Tu 识别的突变体tRNA,有助于提高目标蛋白的产量[42].基于PylRS酶不识别tRNAPyl的反义密码子环特性,tRNAPyl反义密码子环可被任意改造,用于读取不同的密码子[43].通过对tRNAPyl反义密码茎的定向进化,可进一步筛选出翻译效率更高的tRNAPyl突变体(tRNAPly-Opt)[44].未来,随着生化原理解析的深入和相关技术的快速发展,tRNA这一核心翻译元件的开发优化有望进一步突破,实现从源头上推动密码子拓展技术的升级和应用. ...
Rationally evolving tRNAPyl for efficient incorporation of noncanonical amino acids
1
2015
... 理性设计和定向进化策略亦可有效地用于tRNA的改造和优化.例如,tRNA的受体茎是被延伸因子(elongation factor, EF-Tu)识别的特征元素,将大肠杆菌tRNASec的受体茎移植到tRNASer上,建立杂交tRNAUTu成功解决了EF-Tu无法识别tRNASec的问题[40].通过后续的定点诱变,获得了比野生型活性更高的突变体tRNAUTuX,从而推动了硒蛋白的高效合成[41].此外,通过对构建MjtRNATyr的突变体库和正反向筛选,获得了更容易被延伸因子EF-Tu 识别的突变体tRNA,有助于提高目标蛋白的产量[42].基于PylRS酶不识别tRNAPyl的反义密码子环特性,tRNAPyl反义密码子环可被任意改造,用于读取不同的密码子[43].通过对tRNAPyl反义密码茎的定向进化,可进一步筛选出翻译效率更高的tRNAPyl突变体(tRNAPly-Opt)[44].未来,随着生化原理解析的深入和相关技术的快速发展,tRNA这一核心翻译元件的开发优化有望进一步突破,实现从源头上推动密码子拓展技术的升级和应用. ...
Crystal structures of the ribosome in complex with release factors RF1 and RF2 bound to a cognate stop codon
2
2005
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
... [45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
Evolved orthogonal ribosomes enhance the efficiency of synthetic genetic code expansion
1
2007
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
Protein synthesis by ribosomes with tethered subunits
1
2015
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
Ribosome subunit stapling for orthogonal translation in E. coli
1
2015
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
Expanding the genetic code of Escherichia coli with phosphoserine
1
2011
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
Codon reassignment in the Escherichia coli genetic code
3
2010
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
... 目前大部分密码子拓展翻译工具使用UAG琥珀终止密码子作为目标,因此,适配底盘的研究主要围绕UAG密码子及其对应的释放因子.这种适配底盘的构建,主要解决两方面的问题:一是释放因子RF1与翻译工具竞争识别UAG,使得目标蛋白翻译提前终止,降低蛋白得率;二是翻译工具识别其他基因的琥珀密码子,使得其他蛋白质翻译错误延长.针对问题一,可以通过删除释放因子1的基因prfA来解决.prfA基因之前被认为是必需的基因,无法直接被删除.后续有研究表明,删除prfA基因只需将大肠杆菌中7个必需基因中的UAG进行重编[50],或需修复大肠杆菌的释放因子RF2基因prfB中的突变[59].针对问题二,目前大部分非天然氨基酸翻译工具的效率相对较低,过表达外源的翻译工具未见引起严重的细胞胁迫表型.此外,也有研究表明大肠杆菌细胞能在一定程度上耐受翻译错误导致的影响[60].在目前已有的研究基础上来看,针对基因组进行全局系统性精简似乎并非必需,或者只需精简必需基因中的UAG[50].然而,翻译工具的效率随着研究持续开展逐步在提高,配合底盘细胞面向实际应用时,必然要解决细胞内资源利用最优化的问题.因此,UAG的系统性精简对构建高效正交的适配底盘在实际应用场景中则尤其必要[图2(a)].原核与真核系统在系统性精简目标密码子方面均有一定的进展,如Lajoie等利用基因组编辑技术MAGE和接合组装基因组改造技术(conjugative assembly genome engineering,CAGE)将大肠杆菌基因组中所有终止密码子UAG替换为UAA,并删除了RF1[61],使UAG密码子能够特异性地仅用于编码非天然氨基酸[61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
... [50].然而,翻译工具的效率随着研究持续开展逐步在提高,配合底盘细胞面向实际应用时,必然要解决细胞内资源利用最优化的问题.因此,UAG的系统性精简对构建高效正交的适配底盘在实际应用场景中则尤其必要[图2(a)].原核与真核系统在系统性精简目标密码子方面均有一定的进展,如Lajoie等利用基因组编辑技术MAGE和接合组装基因组改造技术(conjugative assembly genome engineering,CAGE)将大肠杆菌基因组中所有终止密码子UAG替换为UAA,并删除了RF1[61],使UAG密码子能够特异性地仅用于编码非天然氨基酸[61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
Efficient multisite unnatural amino acid incorporation in mammalian cells via optimized pyrrolysyl tRNA synthetase/tRNA expression and engineered eRF1
1
2014
... 除了氨酰-tRNA合成酶/tRNA配对之外,核糖体、延伸因子、释放因子等翻译元件也在翻译过程中扮演着非常重要的功能,影响翻译效率及编码氨基酸的特异性.其中,核糖体是蛋白质合成的分子机器;延伸因子识别氨酰-tRNA,并携带其进入核糖体的A位点;多肽链合成完成后通过释放因子(release factor,RF)识别终止密码子实现完整肽链和核糖体从mRNA上的释放[45].有研究通过对大肠杆菌核糖体中16S rRNA的改造来构建正交的核糖体系统[46].也有研究通过对16S rRNA和23S rRNA之间加以物理束缚以避免工程亚基与天然亚基发生交叉装配,保障了工程核糖体和天然核糖体之间的平行功能[47,48].此外,研究发现工程化的核糖体也可以起到阻碍释放因子的作用,促进非天然氨基酸的引入[45].部分非天然氨基酸由于其庞大侧链结构或携带某种电荷,其氨酰-tRNA无法被延伸因子识别或者受到核糖体阻碍导致该非天然氨基酸的编码效率低下.有相关研究则通过改造延伸因子实现了在大肠杆菌中基因编码带负电荷的磷酸化丝氨酸[49].另外,当终止密码子被选择用于编码非天然氨基酸,释放因子的识别也会引起翻译终止的竞争,从而降低目标蛋白的产量[图1(a)].研究人员则通过敲除UAG重编大肠杆菌中的RF1来提高非天然氨基酸的引入效率[50].相比原核生物,真核释放因子eRF1可识别三种终止密码子,研究人员则采取了eRF1改造而非删除的策略,在哺乳动物细胞中开发出针对UAG识别特异性减弱的eRF1突变体,并证实了该策略的可行性[51]. ...
Next-generation genetic code expansion
1
2018
... 用于密码子拓展应用的翻译工具需要配套以相应的底盘细胞来承载其功能的实现.原理上,在未改造的底盘细胞中过量表达密码子拓展翻译工具会导致翻译错误率的提高,从而造成细胞毒性,并产生细胞资源的浪费,不利于后续应用[52].以琥珀终止密码子介导的密码子拓展系统为例,该过程一方面受到翻译终止的竞争,导致目标蛋白得率较低;另一方面造成其他蛋白翻译终止延伸,引起细胞毒性.开发高适配性底盘细胞,避免密码子拓展翻译工具引起的细胞功能紊乱,是建立基于细胞体系的高效密码子拓展系统中必不可少的关键一环.此外,也可以通过利用无细胞体系的方式避免胁迫问题.基于无细胞体系的密码子拓展系统由于摆脱了对适配底盘的依赖,可避免细胞生理胁迫或细胞膜屏障等限制,在如合成毒性蛋白和提高非天然氨基酸利用率方面有其独特优势[53,54].本节将主要围绕基于细胞体系的适配性改造方式展开介绍. ...
Cell-free translation reconstituted with purified components
1
2001
... 用于密码子拓展应用的翻译工具需要配套以相应的底盘细胞来承载其功能的实现.原理上,在未改造的底盘细胞中过量表达密码子拓展翻译工具会导致翻译错误率的提高,从而造成细胞毒性,并产生细胞资源的浪费,不利于后续应用[52].以琥珀终止密码子介导的密码子拓展系统为例,该过程一方面受到翻译终止的竞争,导致目标蛋白得率较低;另一方面造成其他蛋白翻译终止延伸,引起细胞毒性.开发高适配性底盘细胞,避免密码子拓展翻译工具引起的细胞功能紊乱,是建立基于细胞体系的高效密码子拓展系统中必不可少的关键一环.此外,也可以通过利用无细胞体系的方式避免胁迫问题.基于无细胞体系的密码子拓展系统由于摆脱了对适配底盘的依赖,可避免细胞生理胁迫或细胞膜屏障等限制,在如合成毒性蛋白和提高非天然氨基酸利用率方面有其独特优势[53,54].本节将主要围绕基于细胞体系的适配性改造方式展开介绍. ...
无细胞体系非天然蛋白质合成研究进展
1
2018
... 用于密码子拓展应用的翻译工具需要配套以相应的底盘细胞来承载其功能的实现.原理上,在未改造的底盘细胞中过量表达密码子拓展翻译工具会导致翻译错误率的提高,从而造成细胞毒性,并产生细胞资源的浪费,不利于后续应用[52].以琥珀终止密码子介导的密码子拓展系统为例,该过程一方面受到翻译终止的竞争,导致目标蛋白得率较低;另一方面造成其他蛋白翻译终止延伸,引起细胞毒性.开发高适配性底盘细胞,避免密码子拓展翻译工具引起的细胞功能紊乱,是建立基于细胞体系的高效密码子拓展系统中必不可少的关键一环.此外,也可以通过利用无细胞体系的方式避免胁迫问题.基于无细胞体系的密码子拓展系统由于摆脱了对适配底盘的依赖,可避免细胞生理胁迫或细胞膜屏障等限制,在如合成毒性蛋白和提高非天然氨基酸利用率方面有其独特优势[53,54].本节将主要围绕基于细胞体系的适配性改造方式展开介绍. ...
Recent advances in cell-free unnatural protein synthesis
1
2018
... 用于密码子拓展应用的翻译工具需要配套以相应的底盘细胞来承载其功能的实现.原理上,在未改造的底盘细胞中过量表达密码子拓展翻译工具会导致翻译错误率的提高,从而造成细胞毒性,并产生细胞资源的浪费,不利于后续应用[52].以琥珀终止密码子介导的密码子拓展系统为例,该过程一方面受到翻译终止的竞争,导致目标蛋白得率较低;另一方面造成其他蛋白翻译终止延伸,引起细胞毒性.开发高适配性底盘细胞,避免密码子拓展翻译工具引起的细胞功能紊乱,是建立基于细胞体系的高效密码子拓展系统中必不可少的关键一环.此外,也可以通过利用无细胞体系的方式避免胁迫问题.基于无细胞体系的密码子拓展系统由于摆脱了对适配底盘的依赖,可避免细胞生理胁迫或细胞膜屏障等限制,在如合成毒性蛋白和提高非天然氨基酸利用率方面有其独特优势[53,54].本节将主要围绕基于细胞体系的适配性改造方式展开介绍. ...
Encoding multiple unnatural amino acids via evolution of a quadruplet-decoding ribosome
2
2010
... 目前,针对体内密码子拓展系统的适配底盘构建主要通过两种思路实现:一是通过对底盘细胞的基因组进行目标密码子的全基因组精简,以释放出空白密码子来编码新的氨基酸,从而实现密码子拓展;二是通过加入非天然碱基对,使得基因组对应的密码子组合数增加,利用新密码子来编码非天然氨基酸,从而实现对密码子内涵的拓展.此外,亦有研究人员通过改造tRNA和核糖体来实现四联密码子介导基因编码非天然氨基酸过程,达到密码子拓展的目的[55].然而,由于引入的四联密码子会存在于其他mRNA中,从而导致目标氨基酸被非特异性引入其他蛋白质中,并引起该密码子后序列的移码错译.为了解决该问题,四联密码子引入的同时也需要将基因组上其他可形成该密码子组合的序列进行整体替换,本质上属于上文提出的第一种思路.另一种解决方案可通过设计和构建正交的核糖体,保证该核糖体只特异性地识别含有四联密码子的mRNA[55,56,57].此外,最近研究人员也成功利用相分离的策略在空间上对非天然氨基酸引入系统与细胞内源翻译系统进行分离,实现在目标mRNA中的指定位点引入非天然氨基酸,能有效地降低非天然氨基酸引入所带来的细胞功能紊乱程度[58].本节将重点讨论基于全基因组精简和引入非天然核酸这两种策略的适配底盘构建的研究进展. ...
... [55,56,57].此外,最近研究人员也成功利用相分离的策略在空间上对非天然氨基酸引入系统与细胞内源翻译系统进行分离,实现在目标mRNA中的指定位点引入非天然氨基酸,能有效地降低非天然氨基酸引入所带来的细胞功能紊乱程度[58].本节将重点讨论基于全基因组精简和引入非天然核酸这两种策略的适配底盘构建的研究进展. ...
A network of orthogonal ribosome·mRNA pairs
1
2005
... 目前,针对体内密码子拓展系统的适配底盘构建主要通过两种思路实现:一是通过对底盘细胞的基因组进行目标密码子的全基因组精简,以释放出空白密码子来编码新的氨基酸,从而实现密码子拓展;二是通过加入非天然碱基对,使得基因组对应的密码子组合数增加,利用新密码子来编码非天然氨基酸,从而实现对密码子内涵的拓展.此外,亦有研究人员通过改造tRNA和核糖体来实现四联密码子介导基因编码非天然氨基酸过程,达到密码子拓展的目的[55].然而,由于引入的四联密码子会存在于其他mRNA中,从而导致目标氨基酸被非特异性引入其他蛋白质中,并引起该密码子后序列的移码错译.为了解决该问题,四联密码子引入的同时也需要将基因组上其他可形成该密码子组合的序列进行整体替换,本质上属于上文提出的第一种思路.另一种解决方案可通过设计和构建正交的核糖体,保证该核糖体只特异性地识别含有四联密码子的mRNA[55,56,57].此外,最近研究人员也成功利用相分离的策略在空间上对非天然氨基酸引入系统与细胞内源翻译系统进行分离,实现在目标mRNA中的指定位点引入非天然氨基酸,能有效地降低非天然氨基酸引入所带来的细胞功能紊乱程度[58].本节将重点讨论基于全基因组精简和引入非天然核酸这两种策略的适配底盘构建的研究进展. ...
Controlling orthogonal ribosome subunit interactions enables evolution of new function
1
2018
... 目前,针对体内密码子拓展系统的适配底盘构建主要通过两种思路实现:一是通过对底盘细胞的基因组进行目标密码子的全基因组精简,以释放出空白密码子来编码新的氨基酸,从而实现密码子拓展;二是通过加入非天然碱基对,使得基因组对应的密码子组合数增加,利用新密码子来编码非天然氨基酸,从而实现对密码子内涵的拓展.此外,亦有研究人员通过改造tRNA和核糖体来实现四联密码子介导基因编码非天然氨基酸过程,达到密码子拓展的目的[55].然而,由于引入的四联密码子会存在于其他mRNA中,从而导致目标氨基酸被非特异性引入其他蛋白质中,并引起该密码子后序列的移码错译.为了解决该问题,四联密码子引入的同时也需要将基因组上其他可形成该密码子组合的序列进行整体替换,本质上属于上文提出的第一种思路.另一种解决方案可通过设计和构建正交的核糖体,保证该核糖体只特异性地识别含有四联密码子的mRNA[55,56,57].此外,最近研究人员也成功利用相分离的策略在空间上对非天然氨基酸引入系统与细胞内源翻译系统进行分离,实现在目标mRNA中的指定位点引入非天然氨基酸,能有效地降低非天然氨基酸引入所带来的细胞功能紊乱程度[58].本节将重点讨论基于全基因组精简和引入非天然核酸这两种策略的适配底盘构建的研究进展. ...
Designer membraneless organelles enable codon reassignment of selected mRNAs in eukaryotes
1
2019
... 目前,针对体内密码子拓展系统的适配底盘构建主要通过两种思路实现:一是通过对底盘细胞的基因组进行目标密码子的全基因组精简,以释放出空白密码子来编码新的氨基酸,从而实现密码子拓展;二是通过加入非天然碱基对,使得基因组对应的密码子组合数增加,利用新密码子来编码非天然氨基酸,从而实现对密码子内涵的拓展.此外,亦有研究人员通过改造tRNA和核糖体来实现四联密码子介导基因编码非天然氨基酸过程,达到密码子拓展的目的[55].然而,由于引入的四联密码子会存在于其他mRNA中,从而导致目标氨基酸被非特异性引入其他蛋白质中,并引起该密码子后序列的移码错译.为了解决该问题,四联密码子引入的同时也需要将基因组上其他可形成该密码子组合的序列进行整体替换,本质上属于上文提出的第一种思路.另一种解决方案可通过设计和构建正交的核糖体,保证该核糖体只特异性地识别含有四联密码子的mRNA[55,56,57].此外,最近研究人员也成功利用相分离的策略在空间上对非天然氨基酸引入系统与细胞内源翻译系统进行分离,实现在目标mRNA中的指定位点引入非天然氨基酸,能有效地降低非天然氨基酸引入所带来的细胞功能紊乱程度[58].本节将重点讨论基于全基因组精简和引入非天然核酸这两种策略的适配底盘构建的研究进展. ...
RF1 knockout allows ribosomal incorporation of unnatural amino acids at multiple sites
1
2011
... 目前大部分密码子拓展翻译工具使用UAG琥珀终止密码子作为目标,因此,适配底盘的研究主要围绕UAG密码子及其对应的释放因子.这种适配底盘的构建,主要解决两方面的问题:一是释放因子RF1与翻译工具竞争识别UAG,使得目标蛋白翻译提前终止,降低蛋白得率;二是翻译工具识别其他基因的琥珀密码子,使得其他蛋白质翻译错误延长.针对问题一,可以通过删除释放因子1的基因prfA来解决.prfA基因之前被认为是必需的基因,无法直接被删除.后续有研究表明,删除prfA基因只需将大肠杆菌中7个必需基因中的UAG进行重编[50],或需修复大肠杆菌的释放因子RF2基因prfB中的突变[59].针对问题二,目前大部分非天然氨基酸翻译工具的效率相对较低,过表达外源的翻译工具未见引起严重的细胞胁迫表型.此外,也有研究表明大肠杆菌细胞能在一定程度上耐受翻译错误导致的影响[60].在目前已有的研究基础上来看,针对基因组进行全局系统性精简似乎并非必需,或者只需精简必需基因中的UAG[50].然而,翻译工具的效率随着研究持续开展逐步在提高,配合底盘细胞面向实际应用时,必然要解决细胞内资源利用最优化的问题.因此,UAG的系统性精简对构建高效正交的适配底盘在实际应用场景中则尤其必要[图2(a)].原核与真核系统在系统性精简目标密码子方面均有一定的进展,如Lajoie等利用基因组编辑技术MAGE和接合组装基因组改造技术(conjugative assembly genome engineering,CAGE)将大肠杆菌基因组中所有终止密码子UAG替换为UAA,并删除了RF1[61],使UAG密码子能够特异性地仅用于编码非天然氨基酸[61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
Quality control despite mistranslation caused by an ambiguous genetic code
1
2008
... 目前大部分密码子拓展翻译工具使用UAG琥珀终止密码子作为目标,因此,适配底盘的研究主要围绕UAG密码子及其对应的释放因子.这种适配底盘的构建,主要解决两方面的问题:一是释放因子RF1与翻译工具竞争识别UAG,使得目标蛋白翻译提前终止,降低蛋白得率;二是翻译工具识别其他基因的琥珀密码子,使得其他蛋白质翻译错误延长.针对问题一,可以通过删除释放因子1的基因prfA来解决.prfA基因之前被认为是必需的基因,无法直接被删除.后续有研究表明,删除prfA基因只需将大肠杆菌中7个必需基因中的UAG进行重编[50],或需修复大肠杆菌的释放因子RF2基因prfB中的突变[59].针对问题二,目前大部分非天然氨基酸翻译工具的效率相对较低,过表达外源的翻译工具未见引起严重的细胞胁迫表型.此外,也有研究表明大肠杆菌细胞能在一定程度上耐受翻译错误导致的影响[60].在目前已有的研究基础上来看,针对基因组进行全局系统性精简似乎并非必需,或者只需精简必需基因中的UAG[50].然而,翻译工具的效率随着研究持续开展逐步在提高,配合底盘细胞面向实际应用时,必然要解决细胞内资源利用最优化的问题.因此,UAG的系统性精简对构建高效正交的适配底盘在实际应用场景中则尤其必要[图2(a)].原核与真核系统在系统性精简目标密码子方面均有一定的进展,如Lajoie等利用基因组编辑技术MAGE和接合组装基因组改造技术(conjugative assembly genome engineering,CAGE)将大肠杆菌基因组中所有终止密码子UAG替换为UAA,并删除了RF1[61],使UAG密码子能够特异性地仅用于编码非天然氨基酸[61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
Genomically recoded organisms expand biological functions
2
2013
... 目前大部分密码子拓展翻译工具使用UAG琥珀终止密码子作为目标,因此,适配底盘的研究主要围绕UAG密码子及其对应的释放因子.这种适配底盘的构建,主要解决两方面的问题:一是释放因子RF1与翻译工具竞争识别UAG,使得目标蛋白翻译提前终止,降低蛋白得率;二是翻译工具识别其他基因的琥珀密码子,使得其他蛋白质翻译错误延长.针对问题一,可以通过删除释放因子1的基因prfA来解决.prfA基因之前被认为是必需的基因,无法直接被删除.后续有研究表明,删除prfA基因只需将大肠杆菌中7个必需基因中的UAG进行重编[50],或需修复大肠杆菌的释放因子RF2基因prfB中的突变[59].针对问题二,目前大部分非天然氨基酸翻译工具的效率相对较低,过表达外源的翻译工具未见引起严重的细胞胁迫表型.此外,也有研究表明大肠杆菌细胞能在一定程度上耐受翻译错误导致的影响[60].在目前已有的研究基础上来看,针对基因组进行全局系统性精简似乎并非必需,或者只需精简必需基因中的UAG[50].然而,翻译工具的效率随着研究持续开展逐步在提高,配合底盘细胞面向实际应用时,必然要解决细胞内资源利用最优化的问题.因此,UAG的系统性精简对构建高效正交的适配底盘在实际应用场景中则尤其必要[图2(a)].原核与真核系统在系统性精简目标密码子方面均有一定的进展,如Lajoie等利用基因组编辑技术MAGE和接合组装基因组改造技术(conjugative assembly genome engineering,CAGE)将大肠杆菌基因组中所有终止密码子UAG替换为UAA,并删除了RF1[61],使UAG密码子能够特异性地仅用于编码非天然氨基酸[61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
... [61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
Design of a synthetic yeast genome
1
2017
... 目前大部分密码子拓展翻译工具使用UAG琥珀终止密码子作为目标,因此,适配底盘的研究主要围绕UAG密码子及其对应的释放因子.这种适配底盘的构建,主要解决两方面的问题:一是释放因子RF1与翻译工具竞争识别UAG,使得目标蛋白翻译提前终止,降低蛋白得率;二是翻译工具识别其他基因的琥珀密码子,使得其他蛋白质翻译错误延长.针对问题一,可以通过删除释放因子1的基因prfA来解决.prfA基因之前被认为是必需的基因,无法直接被删除.后续有研究表明,删除prfA基因只需将大肠杆菌中7个必需基因中的UAG进行重编[50],或需修复大肠杆菌的释放因子RF2基因prfB中的突变[59].针对问题二,目前大部分非天然氨基酸翻译工具的效率相对较低,过表达外源的翻译工具未见引起严重的细胞胁迫表型.此外,也有研究表明大肠杆菌细胞能在一定程度上耐受翻译错误导致的影响[60].在目前已有的研究基础上来看,针对基因组进行全局系统性精简似乎并非必需,或者只需精简必需基因中的UAG[50].然而,翻译工具的效率随着研究持续开展逐步在提高,配合底盘细胞面向实际应用时,必然要解决细胞内资源利用最优化的问题.因此,UAG的系统性精简对构建高效正交的适配底盘在实际应用场景中则尤其必要[图2(a)].原核与真核系统在系统性精简目标密码子方面均有一定的进展,如Lajoie等利用基因组编辑技术MAGE和接合组装基因组改造技术(conjugative assembly genome engineering,CAGE)将大肠杆菌基因组中所有终止密码子UAG替换为UAA,并删除了RF1[61],使UAG密码子能够特异性地仅用于编码非天然氨基酸[61].在真核系统中,合成基因组里程碑项目人工酵母基因组合成Sc2.0中则设计将全基因组中所有UAG密码子精简为UAA[62],最终构建的合成型酵母则可通过UAG实现密码子功能拓展. ...
The Yin and Yang of codon usage
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Roles for synonymous codon usage in protein biogenesis
1
2015
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon bias as a means to fine-tune gene expression
1
2015
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
The transcription unit architecture of the Escherichia coli genome
1
2009
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
The anti-Shine-Dalgarno sequence drives translational pausing and codon choice in bacteria
1
2012
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Non-optimal codon usage affects expression, structure and function of clock protein FRQ
2
2013
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
... [68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon optimality is a major determinant of mRNA stability
1
2015
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon influence on protein expression in E. coli correlates with mRNA levels
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon usage and 3' UTR length determine maternal mRNA stability in Zebrafish
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Emergent rules for codon choice elucidated by editing rare arginine codons in Escherichia coli
2
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
... [72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Coding-sequence determinants of gene expression in Escherichia coli
1
2009
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon usage is an important determinant of gene expression levels largely through its effects on transcription
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon-resolution analysis reveals a direct and context-dependent impact of individual synonymous mutations on mRNA level
1
2017
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Codon usage determines translation rate in Escherichia coli
1
1989
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Absolute in vivo translation rates of individual codons in Escherichia coli. The two glutamic acid codons GAA and GAG are translated with a threefold difference in rate
1
1991
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Synonymous mutations and ribosome stalling can lead to altered folding pathways and distinct minima
1
2008
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Synonymous codons direct cotranslational folding toward different protein conformations
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Biased codon usage in signal peptides: a role in protein export
1
2009
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Coupling between codon usage, translation and protein export in Escherichia coli
1
2011
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Local slowdown of translation by nonoptimal codons promotes nascent-chain recognition by SRP in vivo
1
2014
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Adaptive evolution of genomically recoded Escherichia coli
1
2018
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Defining synonymous codon compression schemes by genome recoding
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Causes and effects of N-terminal codon bias in bacterial genes
1
2013
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Design, synthesis, and testing toward a 57-codon genome
1
2016
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Total synthesis of Escherichia coli with a recoded genome
1
2019
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Chemical synthesis rewriting of a bacterial genome to achieve design flexibility and biological functionality
1
2019
... 虽然,UAG精简的底盘能适配于目前大部分的翻译工具,但若需要同时编码多个非标准氨基酸,则需要在一个底盘细胞中具有多个空白密码子,实现的方式可通过对编码同一个或多个氨基酸的同义密码子进行系统性的精简[图2(a)].同义密码子的选择有几点因素需要考虑:首先,原有氨酰tRNA合酶不能以目标反密码子为识别因子,以保证其翻译工具tRNA的正交性;其次,在选择目标密码子时也需要考虑有义密码子的摆动性对翻译工具tRNA识别准确性的影响;最后,同义密码子的精简过程中,还需要综合考虑同义密码子在基因组的特定位置可能存在的特定功能[63,64],如对基因内/基因间相互作用[65]、作为转录和翻译调控元件[66,67]、影响核糖体结合能力[68]、调节mRNA水平与结构稳定性[69,70,71,72,73,74,75]、控制翻译速度[76,77],影响蛋白质折叠与分泌[68,78,79,80,81,82]等与基因转录和翻译相关的功能.其中,与第三点相关的研究目前还存在较大的空白,因此实现上仍缺乏足够的理论基础支持.有研究证明,即便是UAG密码子全基因组去除菌株,在某些条件下仍有生长缺陷,而通过适应性进化的方式研究发现,生长缺陷可能与翻译因素相关,间接说明了密码子可能同时带有其他调控功能以影响翻译过程[83].目前,针对原核系统大肠杆菌中对同义密码子精简的影响因素已有了一定的探索[72,84,85],研究表明某些位点的同义密码子的精简会对细胞的活性产生严重的影响.基于这些发现,两组研究人员进一步分别通过基因组合成技术构建只含有57个密码子(进行中)[86]和61个密码子[87]的大肠杆菌.其中后者获得的菌株syn61在倍增时间上比野生菌株慢1.6倍,可以作为一种潜在的多密码子拓展适配底盘.此外,在近期完成的新月柄杆菌基因组合成中[88],也将UUA和UUG密码子在基因组中进行系统性精简作为设计原则之一,结果并未发现对菌株活性有显著影响,亦有潜力作为一种新的适配底盘菌. ...
Hachimoji DNA and RNA: a genetic system with eight building blocks
1
2019
... 自然生物中存在的三联密码子实际上是4种碱基(胸腺嘧啶与尿嘧啶并不同时存在于同一类核酸分子中)排列组合的呈现(即43 = 64 个密码子).由此可知,理论上,若使碱基对的数量增加1对,则会使得潜在的密码子数量理论上可增加至152个(含有非天然核酸的密码子可能具有位置效应,则可用的“空白密码子”将少于理论数量).目前,研究团队已开发出多对能被生物体利用的非天然碱基对[89,90],并证明非天然碱基对可用于构建密码子拓展系统来对非天然氨基酸进行基因编码[91,92,93],第一次以非天然的形式重现了中心法则,为密码子拓展研究和应用提供了一种非常有潜力的新选择[图2(b)]. ...
A semi-synthetic organism with an expanded genetic alphabet
1
2014
... 自然生物中存在的三联密码子实际上是4种碱基(胸腺嘧啶与尿嘧啶并不同时存在于同一类核酸分子中)排列组合的呈现(即43 = 64 个密码子).由此可知,理论上,若使碱基对的数量增加1对,则会使得潜在的密码子数量理论上可增加至152个(含有非天然核酸的密码子可能具有位置效应,则可用的“空白密码子”将少于理论数量).目前,研究团队已开发出多对能被生物体利用的非天然碱基对[89,90],并证明非天然碱基对可用于构建密码子拓展系统来对非天然氨基酸进行基因编码[91,92,93],第一次以非天然的形式重现了中心法则,为密码子拓展研究和应用提供了一种非常有潜力的新选择[图2(b)]. ...
A semi-synthetic organism that stores and retrieves increased genetic information
2
2017
... 自然生物中存在的三联密码子实际上是4种碱基(胸腺嘧啶与尿嘧啶并不同时存在于同一类核酸分子中)排列组合的呈现(即43 = 64 个密码子).由此可知,理论上,若使碱基对的数量增加1对,则会使得潜在的密码子数量理论上可增加至152个(含有非天然核酸的密码子可能具有位置效应,则可用的“空白密码子”将少于理论数量).目前,研究团队已开发出多对能被生物体利用的非天然碱基对[89,90],并证明非天然碱基对可用于构建密码子拓展系统来对非天然氨基酸进行基因编码[91,92,93],第一次以非天然的形式重现了中心法则,为密码子拓展研究和应用提供了一种非常有潜力的新选择[图2(b)]. ...
... 基于现有非天然碱基对的密码子拓展适配底盘菌实际上是一种半合成生物(semisynthetic organism,SSO)[94],构建这种生物除了考虑非天然碱基对本身的性质外,还需要对底盘菌进行针对涉及非天然碱基/核苷酸的转运合成、DNA复制酶、RNA聚合酶、核糖体和与DNA修复(特别是碱基错配修复)相关功能蛋白的改造[95].Romesberg课题组在以大肠杆菌为基础构建半合成生物时,利用Phaeodactylum tricornutum三角褐指藻的三磷酸核苷转运蛋白将含有相应非天然碱基的三磷酸核苷转运至细胞内[94].研究组通过对引入的非天然碱基对进行优化,能够达到在一定程度上不被碱基错配修复机制识别,同时能使用胞内的DNA复制酶、T7 RNA聚合酶以及核糖体,以质粒的形式完成DNA复制、转录和翻译[91,94],最终实现非天然氨基酸的编码. ...
Progress toward a semi-synthetic organism with an unrestricted expanded genetic alphabet
1
2018
... 自然生物中存在的三联密码子实际上是4种碱基(胸腺嘧啶与尿嘧啶并不同时存在于同一类核酸分子中)排列组合的呈现(即43 = 64 个密码子).由此可知,理论上,若使碱基对的数量增加1对,则会使得潜在的密码子数量理论上可增加至152个(含有非天然核酸的密码子可能具有位置效应,则可用的“空白密码子”将少于理论数量).目前,研究团队已开发出多对能被生物体利用的非天然碱基对[89,90],并证明非天然碱基对可用于构建密码子拓展系统来对非天然氨基酸进行基因编码[91,92,93],第一次以非天然的形式重现了中心法则,为密码子拓展研究和应用提供了一种非常有潜力的新选择[图2(b)]. ...
Progress toward eukaryotic semisynthetic organisms: translation of unnatural codons
2
2019
... 自然生物中存在的三联密码子实际上是4种碱基(胸腺嘧啶与尿嘧啶并不同时存在于同一类核酸分子中)排列组合的呈现(即43 = 64 个密码子).由此可知,理论上,若使碱基对的数量增加1对,则会使得潜在的密码子数量理论上可增加至152个(含有非天然核酸的密码子可能具有位置效应,则可用的“空白密码子”将少于理论数量).目前,研究团队已开发出多对能被生物体利用的非天然碱基对[89,90],并证明非天然碱基对可用于构建密码子拓展系统来对非天然氨基酸进行基因编码[91,92,93],第一次以非天然的形式重现了中心法则,为密码子拓展研究和应用提供了一种非常有潜力的新选择[图2(b)]. ...
... 采用非天然碱基对的优势在于可避免对基因组进行大规模的改造,并能实现多密码子拓展,灵活性更强.然而,该策略目前只在原核生物中以质粒DNA的形式实现[94],且其在体内DNA中长时间稳定存在,仍需要依赖一套维持机制(使用CRISPR/Cas系统去除突变的非天然碱基对)[94],整合至基因组后是否能在体内稳定维持非天然碱基对并稳定行使功能仍未见报道.而该策略若应用于真核系统,目前亦只能通过瞬时转化的方法实现非天然氨基酸的编码[93].该策略最终仍依赖于设计开发一套正交的适应于非天然碱基对的DNA复制酶、RNA聚合酶、核糖体及非天然碱基对/核苷酸的合成或转运机器,以保证底盘的复制、转录和翻译活动高效进行.因此,基于非天然核酸的密码子拓展系统仍需要后续系统的优化和完善. ...
A semisynthetic organism engineered for the stable expansion of the genetic alphabet
5
2017
... 基于现有非天然碱基对的密码子拓展适配底盘菌实际上是一种半合成生物(semisynthetic organism,SSO)[94],构建这种生物除了考虑非天然碱基对本身的性质外,还需要对底盘菌进行针对涉及非天然碱基/核苷酸的转运合成、DNA复制酶、RNA聚合酶、核糖体和与DNA修复(特别是碱基错配修复)相关功能蛋白的改造[95].Romesberg课题组在以大肠杆菌为基础构建半合成生物时,利用Phaeodactylum tricornutum三角褐指藻的三磷酸核苷转运蛋白将含有相应非天然碱基的三磷酸核苷转运至细胞内[94].研究组通过对引入的非天然碱基对进行优化,能够达到在一定程度上不被碱基错配修复机制识别,同时能使用胞内的DNA复制酶、T7 RNA聚合酶以及核糖体,以质粒的形式完成DNA复制、转录和翻译[91,94],最终实现非天然氨基酸的编码. ...
... [94].研究组通过对引入的非天然碱基对进行优化,能够达到在一定程度上不被碱基错配修复机制识别,同时能使用胞内的DNA复制酶、T7 RNA聚合酶以及核糖体,以质粒的形式完成DNA复制、转录和翻译[91,94],最终实现非天然氨基酸的编码. ...
... ,94],最终实现非天然氨基酸的编码. ...
... 采用非天然碱基对的优势在于可避免对基因组进行大规模的改造,并能实现多密码子拓展,灵活性更强.然而,该策略目前只在原核生物中以质粒DNA的形式实现[94],且其在体内DNA中长时间稳定存在,仍需要依赖一套维持机制(使用CRISPR/Cas系统去除突变的非天然碱基对)[94],整合至基因组后是否能在体内稳定维持非天然碱基对并稳定行使功能仍未见报道.而该策略若应用于真核系统,目前亦只能通过瞬时转化的方法实现非天然氨基酸的编码[93].该策略最终仍依赖于设计开发一套正交的适应于非天然碱基对的DNA复制酶、RNA聚合酶、核糖体及非天然碱基对/核苷酸的合成或转运机器,以保证底盘的复制、转录和翻译活动高效进行.因此,基于非天然核酸的密码子拓展系统仍需要后续系统的优化和完善. ...
... [94],整合至基因组后是否能在体内稳定维持非天然碱基对并稳定行使功能仍未见报道.而该策略若应用于真核系统,目前亦只能通过瞬时转化的方法实现非天然氨基酸的编码[93].该策略最终仍依赖于设计开发一套正交的适应于非天然碱基对的DNA复制酶、RNA聚合酶、核糖体及非天然碱基对/核苷酸的合成或转运机器,以保证底盘的复制、转录和翻译活动高效进行.因此,基于非天然核酸的密码子拓展系统仍需要后续系统的优化和完善. ...
Synthetic biology: the chemist's approach
1
2019
... 基于现有非天然碱基对的密码子拓展适配底盘菌实际上是一种半合成生物(semisynthetic organism,SSO)[94],构建这种生物除了考虑非天然碱基对本身的性质外,还需要对底盘菌进行针对涉及非天然碱基/核苷酸的转运合成、DNA复制酶、RNA聚合酶、核糖体和与DNA修复(特别是碱基错配修复)相关功能蛋白的改造[95].Romesberg课题组在以大肠杆菌为基础构建半合成生物时,利用Phaeodactylum tricornutum三角褐指藻的三磷酸核苷转运蛋白将含有相应非天然碱基的三磷酸核苷转运至细胞内[94].研究组通过对引入的非天然碱基对进行优化,能够达到在一定程度上不被碱基错配修复机制识别,同时能使用胞内的DNA复制酶、T7 RNA聚合酶以及核糖体,以质粒的形式完成DNA复制、转录和翻译[91,94],最终实现非天然氨基酸的编码. ...
Exploitation of the Escherichia coli lac operon promoter for controlled recombinant protein production
1
2019
... 精准操纵蛋白质功能为细胞生命活动的调控开辟了新的路径,人工控制蛋白质功能的方法包括表达控制与活性控制.传统的方法通常是利用操纵子等启动元件来实现在转录水平上对蛋白质的表达调控[96],而密码子拓展技术可用于开发出在翻译水平上精确控制蛋白质表达的方法.通过在目标蛋白的基因内部引入终止密码子,借助基因密码子拓展工具,即可通过非天然氨基酸的添加或删减来控制全长蛋白的表达与否.例如,通过引入正交的非天然氨基酸编码工具,可实现对基因编辑系统CRISPR-Cas9中关键酶Cas9的表达调控,使得有功能的全长Cas9的表达受外源添加的非天然氨基酸底物控制,从而实现细胞内对于基因编辑过程的开关调控[97]. ...
Switchable genome editing via genetic code expansion
1
2018
... 精准操纵蛋白质功能为细胞生命活动的调控开辟了新的路径,人工控制蛋白质功能的方法包括表达控制与活性控制.传统的方法通常是利用操纵子等启动元件来实现在转录水平上对蛋白质的表达调控[96],而密码子拓展技术可用于开发出在翻译水平上精确控制蛋白质表达的方法.通过在目标蛋白的基因内部引入终止密码子,借助基因密码子拓展工具,即可通过非天然氨基酸的添加或删减来控制全长蛋白的表达与否.例如,通过引入正交的非天然氨基酸编码工具,可实现对基因编辑系统CRISPR-Cas9中关键酶Cas9的表达调控,使得有功能的全长Cas9的表达受外源添加的非天然氨基酸底物控制,从而实现细胞内对于基因编辑过程的开关调控[97]. ...
Optical control of CRISPR/Cas9 gene editing
1
2015
... 此外,利用基因密码子拓展技术亦可以开发出具有时间和空间分辨率的蛋白质功能调控方法.通过把酶活性位点的关键氨基酸替换成携带光保护基团的衍生氨基酸,可实现酶的“光开关”调控.具体而言,氨基酸侧链上的保护基团起到封闭作用,经过固定波长的光线照射后,非天然氨基酸侧链的保护基团被移除,功能基团得到释放,从而恢复蛋白质活性.利用半胱氨酸和赖氨酸作为目标位点,研究证明“光开关”调控策略可以用于调控细胞中烟草蚀刻病毒蛋白酶和Cas9的活性[98].该调控策略同样适用于DNA重组酶活性的精确调控,并被后续应用于斑马鱼胚胎发育过程中细胞谱系的追踪研究[99,100].上述方法需要选择目标蛋白中的特定活性残基,对各种类型的蛋白质均需要进行定制化的策略设计,具有一定的局限性.最近,研究人员发展了更具普适性的蛋白质功能调控技术.具体而言,该新型技术基于可遗传编码非天然氨基酸的“邻近脱笼”策略,结合计算机辅助设计与筛选,可在活体细胞或动物内瞬时激活各类型蛋白质,为许多重要细胞生理过程的研究提供了新的化学生物学工具[101]. ...
Light-activated Cre recombinase as a tool for the spatial and temporal control of gene function in mammalian cells
1
2009
... 此外,利用基因密码子拓展技术亦可以开发出具有时间和空间分辨率的蛋白质功能调控方法.通过把酶活性位点的关键氨基酸替换成携带光保护基团的衍生氨基酸,可实现酶的“光开关”调控.具体而言,氨基酸侧链上的保护基团起到封闭作用,经过固定波长的光线照射后,非天然氨基酸侧链的保护基团被移除,功能基团得到释放,从而恢复蛋白质活性.利用半胱氨酸和赖氨酸作为目标位点,研究证明“光开关”调控策略可以用于调控细胞中烟草蚀刻病毒蛋白酶和Cas9的活性[98].该调控策略同样适用于DNA重组酶活性的精确调控,并被后续应用于斑马鱼胚胎发育过程中细胞谱系的追踪研究[99,100].上述方法需要选择目标蛋白中的特定活性残基,对各种类型的蛋白质均需要进行定制化的策略设计,具有一定的局限性.最近,研究人员发展了更具普适性的蛋白质功能调控技术.具体而言,该新型技术基于可遗传编码非天然氨基酸的“邻近脱笼”策略,结合计算机辅助设计与筛选,可在活体细胞或动物内瞬时激活各类型蛋白质,为许多重要细胞生理过程的研究提供了新的化学生物学工具[101]. ...
Cell-lineage tracing in zebrafish embryos with an expanded genetic code
1
2018
... 此外,利用基因密码子拓展技术亦可以开发出具有时间和空间分辨率的蛋白质功能调控方法.通过把酶活性位点的关键氨基酸替换成携带光保护基团的衍生氨基酸,可实现酶的“光开关”调控.具体而言,氨基酸侧链上的保护基团起到封闭作用,经过固定波长的光线照射后,非天然氨基酸侧链的保护基团被移除,功能基团得到释放,从而恢复蛋白质活性.利用半胱氨酸和赖氨酸作为目标位点,研究证明“光开关”调控策略可以用于调控细胞中烟草蚀刻病毒蛋白酶和Cas9的活性[98].该调控策略同样适用于DNA重组酶活性的精确调控,并被后续应用于斑马鱼胚胎发育过程中细胞谱系的追踪研究[99,100].上述方法需要选择目标蛋白中的特定活性残基,对各种类型的蛋白质均需要进行定制化的策略设计,具有一定的局限性.最近,研究人员发展了更具普适性的蛋白质功能调控技术.具体而言,该新型技术基于可遗传编码非天然氨基酸的“邻近脱笼”策略,结合计算机辅助设计与筛选,可在活体细胞或动物内瞬时激活各类型蛋白质,为许多重要细胞生理过程的研究提供了新的化学生物学工具[101]. ...
Time-resolved protein activation by proximal decaging in living systems
1
2019
... 此外,利用基因密码子拓展技术亦可以开发出具有时间和空间分辨率的蛋白质功能调控方法.通过把酶活性位点的关键氨基酸替换成携带光保护基团的衍生氨基酸,可实现酶的“光开关”调控.具体而言,氨基酸侧链上的保护基团起到封闭作用,经过固定波长的光线照射后,非天然氨基酸侧链的保护基团被移除,功能基团得到释放,从而恢复蛋白质活性.利用半胱氨酸和赖氨酸作为目标位点,研究证明“光开关”调控策略可以用于调控细胞中烟草蚀刻病毒蛋白酶和Cas9的活性[98].该调控策略同样适用于DNA重组酶活性的精确调控,并被后续应用于斑马鱼胚胎发育过程中细胞谱系的追踪研究[99,100].上述方法需要选择目标蛋白中的特定活性残基,对各种类型的蛋白质均需要进行定制化的策略设计,具有一定的局限性.最近,研究人员发展了更具普适性的蛋白质功能调控技术.具体而言,该新型技术基于可遗传编码非天然氨基酸的“邻近脱笼”策略,结合计算机辅助设计与筛选,可在活体细胞或动物内瞬时激活各类型蛋白质,为许多重要细胞生理过程的研究提供了新的化学生物学工具[101]. ...
Deciphering protein kinase specificity through large-scale analysis of yeast phosphorylation site motifs
1
2010
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
Expanding the genetic code of Escherichia coli with phosphoserine
1
2011
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
A flexible codon in genomically recoded Escherichia coli permits programmable protein phosphorylation
1
2015
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
Efficient genetic encoding of phosphoserine and its nonhydrolyzable analog
1
2015
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
A chemical biology route to site-specific authentic protein modifications
1
2016
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
Biosynthesis and genetic encoding of phosphothreonine through parallel selection and deep sequencing
1
2017
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
Genetically encoding phosphotyrosine and its nonhydrolyzable analog in bacteria
1
2017
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
A versatile approach for site-specific lysine acylation in proteins
1
2017
... 翻译后修饰参与调控细胞内众多关键的生命活动调控过程,这些修饰使蛋白质的结构和功能更为丰富, 调节更精细, 作用更专一.因此,基于翻译后修饰的蛋白质结构和功能研究是该领域的一个重点方向.得益于质谱技术的发展,许多翻译后修饰的种类和位点被不断发掘,但是,在体内和体外精确地合成带有修饰的功能蛋白仍然挑战巨大,严重制约了对其进行分子和生化原理的深度研究.以体内合成磷酸化蛋白为例,传统的方法是将丝氨酸/苏氨酸突变为谷氨酸来模拟其磷酸化的作用,但具有作用效果不真实的劣势.此外,磷酸化是一个体内高度动态变化的瞬时过程,单个蛋白中存在众多潜在的修饰位点,且作用相关的激酶和磷酸酶常常未知,也加大了体内和体外合成磷酸化蛋白的难度[102].利用基因密码子拓展技术可实现对目标蛋白中指定位点进行真实的翻译后修饰,已经成功实现丝氨酸、色氨酸及络氨酸的磷酸化修饰.通过利用古菌中磷酸化丝氨酸合成酶SepRS和改造的tRNASep,并对延伸因子EF-Tu进行定向进化,科学家在大肠杆菌中实现了由终止密码子UAG介导的磷酸化丝氨酸合成[103].后续实验表明,通过对上述翻译元件的进一步改造和定向进化,以及利用UAG密码子被系统重编的底盘细胞,密码子拓展技术可以更为高效地基因编码携带磷酸化丝氨酸的蛋白质[104,105].此外,磷酸化的丝氨酸可以转化为脱氢丙氨酸,因其具有不饱和键,可与带有各种翻译后修饰的侧链基团连接,用于体外合成具有真实修饰的蛋白质,应用前景广阔[106].通过构建磷酸化苏氨酸生物合成通路,并对SepRS/tRNASep工具配对开展连续的定向进化,辅助以深度测序分析介导的并行正向筛选策略,高效基因编码磷酸化苏氨酸的方法亦被开发出来[107].此外,利用基于非天然氨基酸的脱保护和前肽策略,不同的团队成功地开发了提高大肠杆菌体内磷酸化酪氨酸和类似物的浓度的方法,并实现了合成指定位点上携带磷酸化酪氨酸及其类似物的蛋白质[108].除了用于合成磷酸化蛋白,基因密码子拓展技术亦可合成乙酰化、泛素化和甲基化修饰的赖氨酸[7].上述翻译后修饰的氨基酸既可以被直接引入到蛋白质中的指定位点,也可以通过后续的选择性化学反应来实现[109].综上,基因密码子拓展技术已经成功地应用于各类型的翻译后修饰研究,为进一步理解其作用机制和生理功能的科研或者临床研究奠定了基础. ...
The green fluorescent protein
1
1998
... 荧光显影在蛋白质追踪和定位研究中有着非常广泛的应用,通过荧光显影可以在细胞甚至细胞器层面上对目标蛋白进行准确的定位.常规的荧光显影方法主要使用荧光蛋白与小分子化合物探针.虽然借助各种类型的荧光蛋白可有效地用于荧光成像和追踪[110,111],但与荧光蛋白的融合可能会改变目标蛋白的构象或结构,影响后续的结果分析.虽然小分子化合物探针灵敏且稳定性高,但是通常无法特异性地结合在目标蛋白上.通过基因密码子拓展技术可以实现对目标蛋白的显影示踪.具体而言,在不影响目标蛋白功能的情况下,可将携带高化学反应性基团的非天然氨基酸引入到目标蛋白的指定位点,通过特定的化学反应(如点击化学)可实现蛋白质与荧光探针的生物正交结合,用于后续荧光成像.例如,含降冰片烯的赖氨酸衍生物可以与四嗪类荧光探针快速结合[112],反式环辛烯赖氨酸则可以与类罗丹明的荧光探针产生正交反应[113],用于蛋白质显影追踪.密码子拓展技术在蛋白质显影追踪方面有两点显著的优势:经过设计与筛选后的非天然氨基酸侧链基团与荧光探针具有高选择性,保证两者可以进行高效准确的生物正交反应;密码子拓展技术可以将非天然氨基酸引入到目标蛋白的非关键位点,从而尽量避免对蛋白质的结构和功能产生潜在影响. ...
A monomeric red fluorescent protein
1
2002
... 荧光显影在蛋白质追踪和定位研究中有着非常广泛的应用,通过荧光显影可以在细胞甚至细胞器层面上对目标蛋白进行准确的定位.常规的荧光显影方法主要使用荧光蛋白与小分子化合物探针.虽然借助各种类型的荧光蛋白可有效地用于荧光成像和追踪[110,111],但与荧光蛋白的融合可能会改变目标蛋白的构象或结构,影响后续的结果分析.虽然小分子化合物探针灵敏且稳定性高,但是通常无法特异性地结合在目标蛋白上.通过基因密码子拓展技术可以实现对目标蛋白的显影示踪.具体而言,在不影响目标蛋白功能的情况下,可将携带高化学反应性基团的非天然氨基酸引入到目标蛋白的指定位点,通过特定的化学反应(如点击化学)可实现蛋白质与荧光探针的生物正交结合,用于后续荧光成像.例如,含降冰片烯的赖氨酸衍生物可以与四嗪类荧光探针快速结合[112],反式环辛烯赖氨酸则可以与类罗丹明的荧光探针产生正交反应[113],用于蛋白质显影追踪.密码子拓展技术在蛋白质显影追踪方面有两点显著的优势:经过设计与筛选后的非天然氨基酸侧链基团与荧光探针具有高选择性,保证两者可以进行高效准确的生物正交反应;密码子拓展技术可以将非天然氨基酸引入到目标蛋白的非关键位点,从而尽量避免对蛋白质的结构和功能产生潜在影响. ...
Genetically encoded norbornene directs site-specific cellular protein labelling via a rapid bioorthogonal reaction
1
2012
... 荧光显影在蛋白质追踪和定位研究中有着非常广泛的应用,通过荧光显影可以在细胞甚至细胞器层面上对目标蛋白进行准确的定位.常规的荧光显影方法主要使用荧光蛋白与小分子化合物探针.虽然借助各种类型的荧光蛋白可有效地用于荧光成像和追踪[110,111],但与荧光蛋白的融合可能会改变目标蛋白的构象或结构,影响后续的结果分析.虽然小分子化合物探针灵敏且稳定性高,但是通常无法特异性地结合在目标蛋白上.通过基因密码子拓展技术可以实现对目标蛋白的显影示踪.具体而言,在不影响目标蛋白功能的情况下,可将携带高化学反应性基团的非天然氨基酸引入到目标蛋白的指定位点,通过特定的化学反应(如点击化学)可实现蛋白质与荧光探针的生物正交结合,用于后续荧光成像.例如,含降冰片烯的赖氨酸衍生物可以与四嗪类荧光探针快速结合[112],反式环辛烯赖氨酸则可以与类罗丹明的荧光探针产生正交反应[113],用于蛋白质显影追踪.密码子拓展技术在蛋白质显影追踪方面有两点显著的优势:经过设计与筛选后的非天然氨基酸侧链基团与荧光探针具有高选择性,保证两者可以进行高效准确的生物正交反应;密码子拓展技术可以将非天然氨基酸引入到目标蛋白的非关键位点,从而尽量避免对蛋白质的结构和功能产生潜在影响. ...
A near-infrared fluorophore for live-cell super-resolution microscopy of cellular proteins
1
2013
... 荧光显影在蛋白质追踪和定位研究中有着非常广泛的应用,通过荧光显影可以在细胞甚至细胞器层面上对目标蛋白进行准确的定位.常规的荧光显影方法主要使用荧光蛋白与小分子化合物探针.虽然借助各种类型的荧光蛋白可有效地用于荧光成像和追踪[110,111],但与荧光蛋白的融合可能会改变目标蛋白的构象或结构,影响后续的结果分析.虽然小分子化合物探针灵敏且稳定性高,但是通常无法特异性地结合在目标蛋白上.通过基因密码子拓展技术可以实现对目标蛋白的显影示踪.具体而言,在不影响目标蛋白功能的情况下,可将携带高化学反应性基团的非天然氨基酸引入到目标蛋白的指定位点,通过特定的化学反应(如点击化学)可实现蛋白质与荧光探针的生物正交结合,用于后续荧光成像.例如,含降冰片烯的赖氨酸衍生物可以与四嗪类荧光探针快速结合[112],反式环辛烯赖氨酸则可以与类罗丹明的荧光探针产生正交反应[113],用于蛋白质显影追踪.密码子拓展技术在蛋白质显影追踪方面有两点显著的优势:经过设计与筛选后的非天然氨基酸侧链基团与荧光探针具有高选择性,保证两者可以进行高效准确的生物正交反应;密码子拓展技术可以将非天然氨基酸引入到目标蛋白的非关键位点,从而尽量避免对蛋白质的结构和功能产生潜在影响. ...
Antibody-drug conjugates in cancer therapy
1
2013
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Drug-conjugated antibodies for the treatment of cancer
1
2013
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Addition of the keto functional group to the genetic code of Escherichia coli
1
2003
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Click chemistry: diverse chemical function from a few good reactions
1
2001
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Hydrazino-Pictet-Spengler ligation as a biocompatible method for the generation of stable protein conjugates
1
2013
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Structural basis of furan-amino acid recognition by a polyspecific aminoacyl-tRNA-synthetase and its genetic encoding in human cells
1
2014
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Adoptive T-cell therapy: adverse events and safety switches
1
2014
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Versatile strategy for controlling the specificity and activity of engineered T cells
1
2016
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Principles underlying rational design of live attenuated influenza vaccines
1
2012
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
Generation of influenza A viruses as live but replication-incompetent virus vaccines
1
2016
... 通过基因密码子拓展技术向细胞因子、抗体、受体蛋白等免疫相关蛋白中引入各类型的非天然氨基酸为新型治疗策略开辟了新的领域.抗体作为一种具有高特异性识别能力的蛋白质,可以将药物分子靶向性地带到靶向作用细胞,以减少对正常细胞的伤害.早期抗体耦联药物通过化学修饰后与抗体的赖氨酸或半胱氨酸进行反应耦联,实现药物分子的靶向传输[114,115].但非特异性耦联方式会导致抗体上携带的药物分子数量不均匀,进而影响药效和导致细胞毒性.在新一代抗体耦联药物研发过程中,非天然氨基酸(例如对乙酰苯丙氨酸和叠氮苯丙氨酸)可作为正交的耦联反应位点,与药物发生特异性的结合,从而精确控制药物抗体比例.使用肟连接与无铜点击化学可以将药物准确地耦联在抗体中非天然氨基酸的指定位点[116,117].此外,一些条件更为温和的耦联反应被相继开发出来.例如,增加皮克特-斯宾格勒(Pictet-Spengler,P-S)反应使肟连接反应可以在中性pH条件下完成,或是使用呋喃基的非天然氨基酸进行光交联反应实现小分子化合物的耦联[118,119].嵌合抗原受体T细胞(chimeric antigen receptor-T,CAR-T)免疫疗法是一种治疗肿瘤的新型精准靶向疗法,避免细胞因子释放综合征是目前开发高安全性CAR-T免疫疗法的研究重点[120].基因密码子拓展技术可用于控制工程化T细胞的特异性和活性,通过利用开关分子来连接T细胞和肿瘤细胞,为开发新一代CAR-T免疫疗法奠定基础[121].此外,基因密码子拓展技术还可以用于新一代疫苗的研发.传统的疫苗制作需要对活病毒进行减活或者灭活处理,病毒蛋白结构在灭活过程中一旦被破坏,则可能难以达到理想的接种效果[122].科学家把病毒基因中不易返祖的位点突变成UAG终止密码子,利用密码子拓展技术实现病毒在特殊细胞系的增殖,从而制备与正常病毒相似免疫原性的非天然病毒[123].这些病毒不能在正常细胞中扩增,可显著提升疫苗的安全性,具有巨大的应用潜力. ...
A fluorescent, genetically engineered microorganism that degrades organophosphates and commits suicide when required
1
2009
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
Dual system to reinforce biological containment of recombinant bacteria designed for rhizoremediation
1
2001
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
Building-in biosafety for synthetic biology
1
2013
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
Alternative biochemistries for alien life: basic concepts and requirements for the design of a robust biocontainment system in genetic isolation
1
2019
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
Functional replacement of histidine in proteins to generate noncanonical amino acid dependent organisms
1
2018
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
Biocontainment of genetically modified organisms by synthetic protein design
1
2015
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
A general strategy for engineering noncanonical amino acid dependent bacterial growth
1
2019
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
Recoded organisms engineered to depend on synthetic amino acids
1
2015
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...
An engineered bacterium auxotrophic for an unnatural amino acid: a novel biological containment system
1
2015
... 近些年来,合成生物学突取得了突飞猛进的发展,基因改造生物在生物技术领域发挥着越来越举足轻重的作用,科学家与大众对生物安全的关注也被提升至新的高度.基于非天然氨基酸的蛋白质表达调控和蛋白质从头设计策略为生物防逃逸技术打开了一个崭新的研发视角.生物防控手段可依赖于遗传隔离、营养缺陷型调控、基因回路设计等思路[124,125,126],但上述方法的有效性易被自然突变、环境补充和水平基因转移等因素打破[127].基因密码子拓展技术可用于控制细胞中必需蛋白的表达或者功能,进而构建出依赖于非天然氨基酸的生命体.例如,通过把甘露糖-6-磷酸异构酶这一必需蛋白中关键的组氨酸替换成为组氨酸类似物,科学家成功地构建出生长依赖于外源氨基酸的大肠杆菌[128].上述策略虽然有效,但是只适用于特定类型的蛋白质(如前文提到的金属结合蛋白).通过对目标蛋白的关键区域进行重新设计或者定向进化,研究人员利用密码子拓展技术成功获得了功能依赖于某种非天然氨基酸的新型蛋白,该策略具有更高的普适性,并可有效地避免基因改造生物逃逸到自然环境中[129,130].值得指出的是,上述策略将必需基因中特定氨基酸对应的密码子突变成为终止密码子,若对应的mRNA发生回复突变等情况会使得防逃逸策略的有效性丧失.利用基因组重编的大肠杆菌作为基因密码子拓展技术的底盘,研究团队系统地测试了大肠杆菌众多必需基因中不同位点引入非天然氨基酸后对于生物防控策略的有效性,并发现多个位点和基因的组合可有效地降低非天然氨基酸依赖型生长的逃逸概率[131].此外,通过往细胞中引入毒素-抗毒素表达系统,并利用非天然氨基酸的加减作为抗毒素蛋白表达的开关,亦可构建出有效的生物防控方法[132].综上所述,利用基因密码子拓展技术,通过巧妙地选择目标蛋白的种类并对其进行设计或改造,基于非天然氨基酸的新型生物防控策略为本领域的发展带来了新的动能. ...



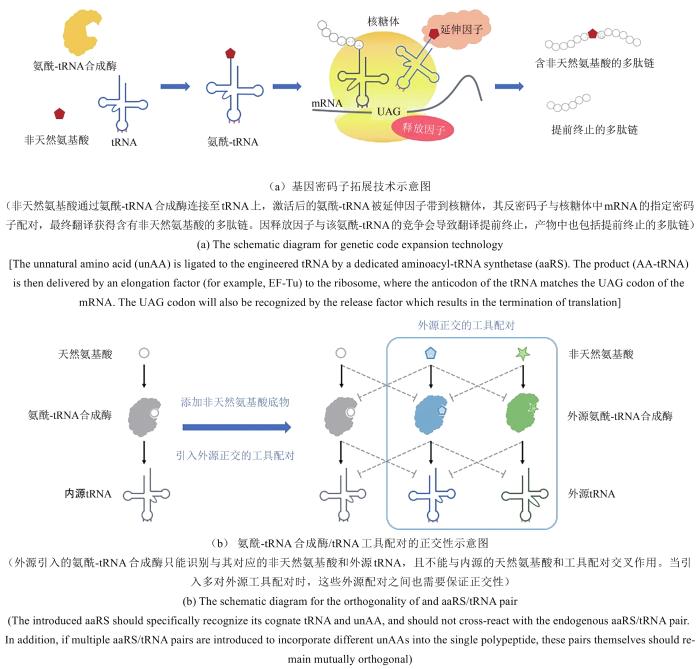
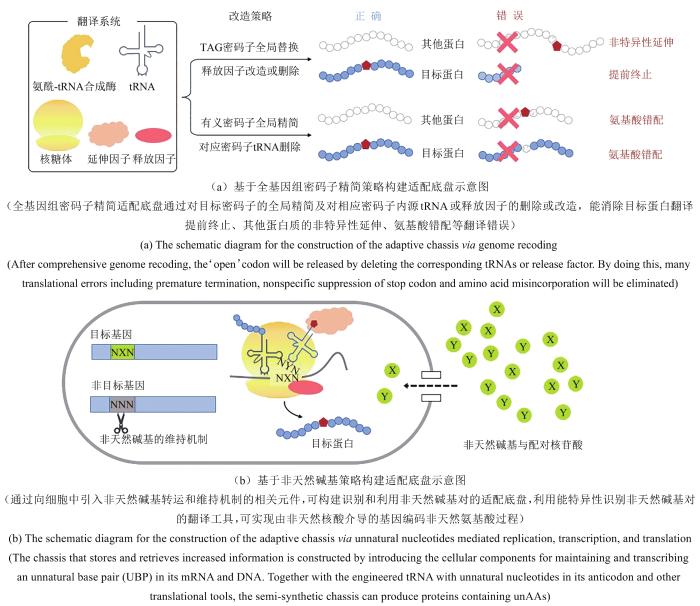


{kind=link}
{kind=link}
{kind=link}
{kind=link}