|
||
|
DeepSeek model analysis and its applications in AI-assistant protein engineering
Synthetic Biology Journal
2025, 6 (3):
636-650.
DOI: 10.12211/2096-8280.2025-041
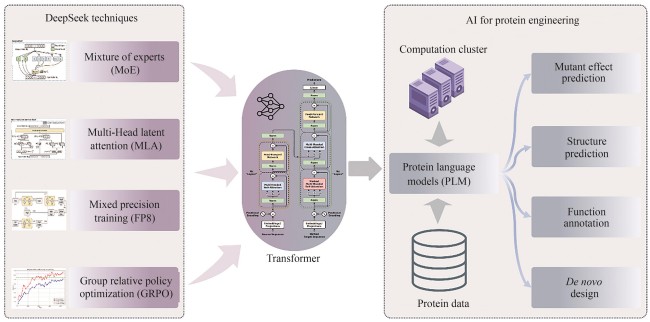
In early 2025, Hangzhou DeepSeek AI Foundation Technology Research Co., Ltd. released and open-sourced its independently developed DeepSeek-R1 conversational large language model. This model exhibits extremely low inference costs and outstanding chain-of-thought reasoning capabilities, performing comparably to, and in some tasks surpassing, proprietary models like GPT-4o and o1. This achievement has garnered significant international attention. Furthermore, DeepSeek’s excellent performance in Chinese conversations and its free-for-commercial-use strategy have ignited a wave of deployment and application within China, thereby promoting the widespread adoption and development of AI technology. This work systematically analyzes the architectural design, training methodology, and inference mechanisms of the DeepSeek model, exploring the transfer potential and application prospects of its core technologies in AI-assistant protein research. The DeepSeek model integrates several cutting-edge, independently innovated technologies, including a multi-head latent attention mechanism, mixture-of-experts (MoE) with load balancing, and low-precision training. These innovations have substantially reduced the training and inference costs for Transformer models. Although DeepSeek was originally designed for human language understanding and generation, its optimization techniques hold significant reference value for pre-trained language models with proteins, which are also based on the Transformer architecture. By leveraging the key technologies employed in DeepSeek, protein language models are expected to achieve substantial reductions in training and inference costs.
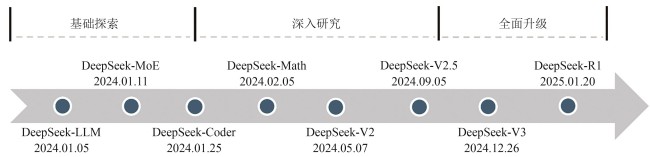
Fig. 1
History with the development of DeepSeek models
Extracts from the Article
DeepSeek系列重要的模型发展历史可以分为基础探索、深入研究和全面升级三个阶段(图1)。
Other Images/Table from this Article
|

{kind=link}