|
||
|
DeepSeek model analysis and its applications in AI-assistant protein engineering
Synthetic Biology Journal
2025, 6 (3):
636-650.
DOI: 10.12211/2096-8280.2025-041
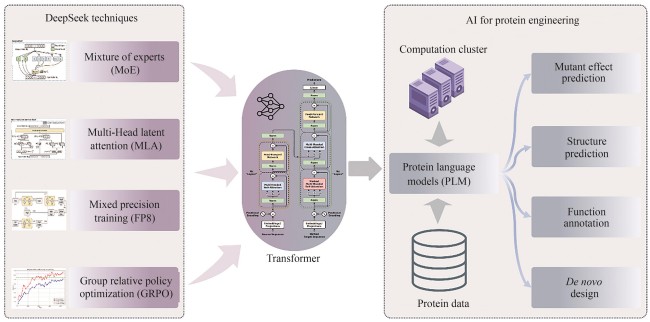
In early 2025, Hangzhou DeepSeek AI Foundation Technology Research Co., Ltd. released and open-sourced its independently developed DeepSeek-R1 conversational large language model. This model exhibits extremely low inference costs and outstanding chain-of-thought reasoning capabilities, performing comparably to, and in some tasks surpassing, proprietary models like GPT-4o and o1. This achievement has garnered significant international attention. Furthermore, DeepSeek’s excellent performance in Chinese conversations and its free-for-commercial-use strategy have ignited a wave of deployment and application within China, thereby promoting the widespread adoption and development of AI technology. This work systematically analyzes the architectural design, training methodology, and inference mechanisms of the DeepSeek model, exploring the transfer potential and application prospects of its core technologies in AI-assistant protein research. The DeepSeek model integrates several cutting-edge, independently innovated technologies, including a multi-head latent attention mechanism, mixture-of-experts (MoE) with load balancing, and low-precision training. These innovations have substantially reduced the training and inference costs for Transformer models. Although DeepSeek was originally designed for human language understanding and generation, its optimization techniques hold significant reference value for pre-trained language models with proteins, which are also based on the Transformer architecture. By leveraging the key technologies employed in DeepSeek, protein language models are expected to achieve substantial reductions in training and inference costs.
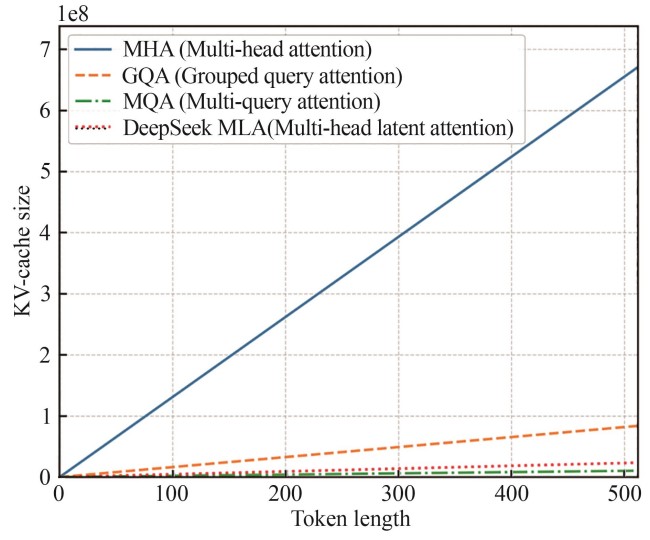
Fig. 3
Comparison of KV-Cache sizes among different attention mechanisms
Extracts from the Article
针对上述挑战,DeepSeek团队提出了一种新的注意力机制——多头潜在注意力机制(MLA)。该机制通过将键值向量压缩至一个固定维度的隐空间中,并在注意力计算前将其还原至原始表示空间,从而有效降低了KV-Cache的显存占用。实验表明,MLA能够在保持高质量生成的同时,显著减少模型推理时的显存消耗。尽管该方法在训练阶段引入了额外的压缩编码成本,但在推理过程中,得益于矩阵乘法的结合律特性,可以将压缩与注意力计算融合为一次高效的矩阵操作,从而不会增加额外的计算负担。图3以注意力头数64,模型隐层大小8192,层数80的Transformer模型为例展示了不同注意力机制(MQA、GQA与MLA)的KV-Cache显存占用随输出长度变化的趋势,其中GQA的分组数为8,计算公式为DeepSeek-V2中给出的注意力复杂度计算公式[12]。可以看出,随着序列长度的增加,MLA所需的缓存空间明显低于MHA及GQA,略高于MQA。然而,MLA在生成质量方面优于MQA。
Other Images/Table from this Article
|

{kind=link}