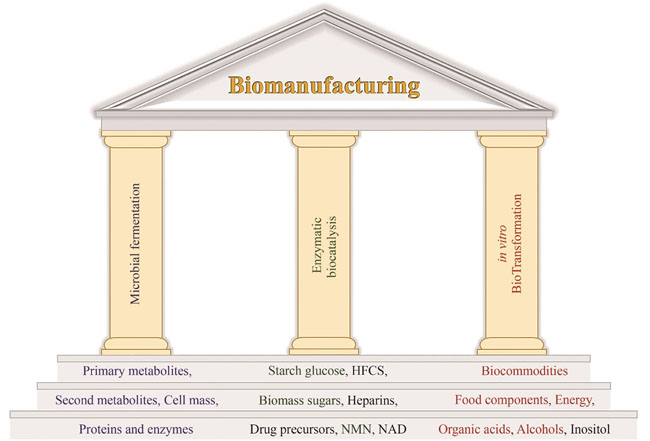
Huge challenges, such as food security, energy security, climate change, dual-carbon target, and so on, motivate human society to seek disruptive and innovative solutions. In vitro biotransformation (ivBT), bridging the gap between whole-cell-based fermentation and enzyme-based biocatalysis, is an emerging biomanufacturing platform designed for the production of biocommodities (e.g., synthetic starch, healthy sweeteners, organic acids, etc.) and bioenergy. In ivBT, in vitro synthetic enzymatic biosystem (ivSEB) is its high-efficiency biocatalyst. Based on the Chinese philosophy that “Tao is simple”, ivSEB is the in vitro reconstruction of artificial (non-natural) enzymatic pathways with a number of natural enzymes, artificial enzymes, and/or (biomimetic or natural) coenzymes, and/or artificial membrane, without living cell’s constraints, such as cell duplication, bioenergetics, basic metabolisms, regulation, and so on. ivBT enables it to surpass the limitations of whole-cell fermentation and has multiple advantages, such as theoretical product yield, at least 10-time volumetric productivity, tolerance to toxic substrate/product, and so on. This review defines the concept of ivBT, presents its design principles, distinguishes it from other seemingly-like concepts, such as cell-free protein synthesis and cascade enzyme biocatalysis, introduces several representative examples, and discusses its challenges and opportunities. The development of ivBT is based on the linear strategy of “Design-Build-GoNG-Optimization”, leading to super-biomanufacturing machines that can meet national needs, such as food security and new energy system. To address food security, we propose two out-of-the-box solutions: (1) in vitro biotransformation of cellulose to starch, possibly increasing the starch supply by a factor of 10; (2) artificial starch synthesis from CO2 by combining ivBT and chemical catalysis. Furthermore, the revolutionary production of starch could open a door to the starch-based carbohydrate economy, wherein starch is a high-density hydrogen carrier, more than 2.5 times that of compressed hydrogen, and an ultra-high electricity storage compound, more than 10 times of lithium-ion battery. In a word, ivBT featuring ultra-high energy efficiency and potentially-low-cost production could become a third industrial biomanufacturing platform and help solve huge challenges.