数据集 Data set | 训练集 Training set | 测试集 Test set |
|---|
完整菌落图像 Complete colony images | 34 | 4 | 挑选出小图像块 Small image blocks Selected | 5160 | 1466 |
Table 1
Distribution of the dataset
Extracts from the Article
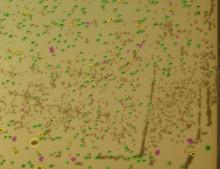
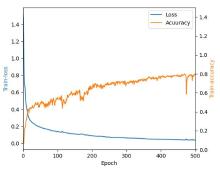
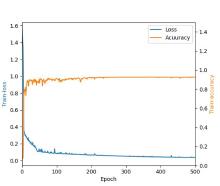
由于真实实验数据拍摄的是一张大图。标签制作是标记的大图,共标记样本量大图38张,网络模型要求图像输入尺寸是256×256像素,采用有重叠的滑动窗口方式将完整菌落图片及其掩码图裁剪成图像块,在大图像块及其掩码图像块上有覆盖的滑动窗口裁剪小图像块和小图像块掩码,滑动窗口步长为100,小图像块尺寸为256×256像素。从裁剪的小图像块中挑选模型的训练集和验证集,将挑出的训练集小图像块生成训练数据集,将小图像块对应的掩码图像块生成训练标签集。数据集的分布情况见表1,表中第二列统计训练样本的训练计样本量:大图34张,挑256×256图像块5160张;第二列测试集样本量:大图4张,256×256图像块1466张。训练集按照训练数据与验证数据按4∶1的比例划分,训练得到菌落训练曲线如图10所示,epoch=500,图中Loss从1.6降到0.8左右,准确率最终达到0.92。菌落语义分割模型推理生成灰度图像如图11所示,利用图像分割模型测试测试集,IOU为0.75,由于测试样本里只标注了菌落,没有标注灰尘等其他,基本不存在假阳性,模型的假阴率是0.16。
Other Images/Table from this Article
|